](https://deep-paper.org/en/paper/file-3314/images/cover.png)
引言
想象一下你正在给朋友发短信。他们回复说: “你无法改变一个人的本质,但你可以爱他们 #sadly (悲伤地) 。”
你会如何分类这里的各种情感?标准的情感分析工具可能会看到“爱”这个词就将其标记为 快乐 (Joy) , 或者看到标签就将其标记为 悲伤 (Sadness) 。 但人类读者能察觉到更微妙的东西: 一种听天由命的感觉,一种对现实的艰难接受。正确的标签很可能是 悲观 (Pessimism) 。
像 GPT-4 或 T5 这样的大型语言模型 (LLM) 已经非常擅长理解文本,但它们在处理这种细粒度的情感细微差别时仍然很吃力。当答案需要通过字里行间来解读时,它们经常会产生幻觉或默认为像“中性”这样的“安全”标签。
在这篇文章中,我们将深入探讨一篇引人入胜的论文,题为 “Linear Layer Extrapolation for Fine-Grained Emotion Classification” (用于细粒度情感分类的线性层外推) 。 研究人员提出了一种新颖的方法来提取这些细微的情感,不是通过训练更大的模型,而是通过改变我们读取模型内部状态的方式。他们从几何学的角度重新解释了一种称为 对比解码 (Contrastive Decoding) 的技术,将模型的各个层视为一条轨迹,并将预测“外推”到一个理论上的未来层。
背景: Transformer 的分层“大脑”
要理解这篇论文,我们首先需要可视化 Transformer 模型是如何处理信息的。
当你将一个句子输入到像 BERT 或 T5 这样的模型中时,它会穿过一堆层 (例如 12 层、24 层或 48 层) 。
- 早期层: 这些层通常关注表面特征——句法、语法和基本的词汇联想。
- 中间层: 这些层开始构建上下文和含义。
- 后期 (专家) 层: 这些层提炼理解,处理复杂的推理、事实性和细微差别。
提前退出 (Early Exiting) 的概念
通常,我们只关心最后一层的输出。然而,我们可以执行“提前退出”。这意味着我们可以获取模型在 (比如说) 第 15 层的内部状态,给它附加一个分类器,然后问: “你认为现在的情感是什么?”
研究表明,“事实性”和“细微差别”的能力出现在较后的层中。这导致了一种名为 DoLa (Decoding by Contrasting Layers,通过层对比进行解码) 技术的发展。其直觉很简单: 如果早期层 (“业余者”) 认为文本只是“悲伤 (Sad)”,但最终层 (“专家”) 认为它是“悲观 (Pessimistic)”,我们应该强调这种差异。我们希望减去业余者的基本直觉,以揭示专家的深刻见解。
核心方法: 从减法到外推
这篇论文的作者采用了对比解码的概念,并赋予了它严谨的数学和几何基础。他们认为,我们不应该仅仅从专家中减去业余者;我们应该将它们视为一条线上的点,并向更远处外推。
1. 标准的对比方法
在标准的对比解码中,我们有两个概率分布:
- \(p_e\): 专家 (最终层) 概率。
- \(p_a\): 业余者 (早期层) 概率。
我们希望提高那些专家比业余者更有信心的类别的分数。标准公式如下所示:
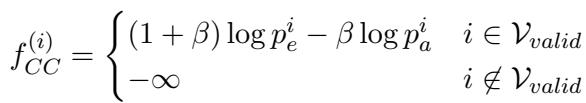
在这里,\(\beta\) 是一个超参数,控制我们惩罚业余者的程度。如果 \(\beta\) 为 0,我们就只使用专家。随着 \(\beta\) 增加,我们减去更多业余者的分数。
为了确保模型不会仅仅因为业余者讨厌某个词就选择一个极不可能的词而导致失控,作者使用了 自适应合理性约束 (Adaptive Plausibility Constraint) 。 这过滤了有效的候选类别 (\(\mathcal{V}_{valid}\)),只包括那些专家认为在一定程度上可能的类别:
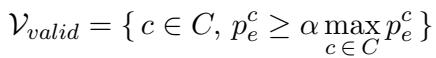
基本上,我们只对专家猜测的顶层候选项执行此对比操作。
2. 选择业余者
哪一层早期层应该作为“业余者”?如果你选择太早的层 (第 1 层) ,它什么都不知道,所以对比它是无用的。如果你选择太接近末尾的层 (48 层模型中的第 47 层) ,它与专家几乎相同,差异为零。
作者使用了一种动态选择方法。他们将最终层的输出分布与几个早期层进行比较,并选择差异最大 (距离最大) 的那一层。
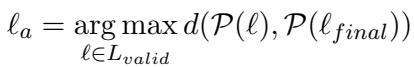
这确保了业余者层具有特定的、明显的观点,而该观点已被专家修正。
3. 新颖的见解: 线性外推
这是论文最关键的贡献。作者没有将图 2 中的公式仅仅视为“惩罚减法”,而是对其进行了几何可视化。
想象模型的层是 x 轴上的阶梯。模型对特定情感的信心 (即“logit 分数”) 在 y 轴上。
- 在层 \(\ell_a\) (业余者) ,“悲观”的分数很低。
- 在层 \(L\) (专家) ,“悲观”的分数较高。
如果我们画一条穿过这两点的线,我们可以看到一条轨迹。随着层数加深,模型正在学习该文本是悲观的。 为什么要停在最后一层?
作者建议将这条线向前投影到一个理论上的目标层 \(\ell_t\) (例如,48 层模型中的第 60 层) 。这就是 线性层外推 (Linear Layer Extrapolation) 。
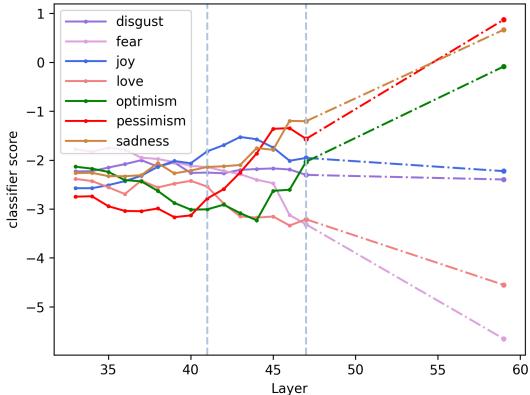
如上图所示,通过将线延伸过最后一层,“悲观” (虚线) 的分数直线上升,最终超过了“悲伤”。这使得模型能够正确地将预测翻转为更细微的类别。
4. 外推的数学原理
让我们将其形式化。我们有一条线穿过业余者分数 \(f(\ell_a)\) 和专家分数 \(f(L)\)。这条线上特定层 \(\ell\) 的方程是:
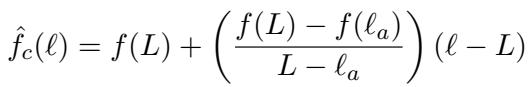
作者发现,如果你将目标层 \(\ell_t\) 代入这个线性方程,它重新排列后看起来这就完全像标准的对比解码公式:
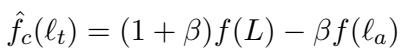
这是一个强有力的启示。这意味着 对比解码实际上就是伪装的线性外推 。
5. 动态 Beta (\(\beta\)) 选择
在以前的工作中,\(\beta\) (对比强度) 是一个你需要猜测的静态数字 (例如,“让我们试试 0.5”) 。
然而,由于作者有效地将 \(\beta\) 与层的几何形状联系起来,他们现在可以动态地定义 \(\beta\)。如果业余者层距离专家很远,其斜率将不同于距离很近的情况。
目标层 \(\ell_t\)、业余者层 \(\ell_a\) 和 \(\beta\) 之间的关系是:
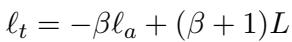
我们可以重新排列它来求解 \(\beta\):
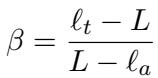
这为什么重要? 研究人员不再盲目选择固定的惩罚 \(\beta\),而是决定一个目标层 (例如,“我想看看如果这个模型多出 10 层会是什么样”) 。他们设定 \(\ell_t\),并且由于业余者层 \(\ell_a\) 对于每个输入都会动态变化 (基于哪一层与专家分歧最大) ,\(\beta\) 值会自动为每个样本进行自我调整。
这种 动态 \(\beta\) 使得该方法更加稳定和鲁棒。
实验与结果
研究人员在几个具有挑战性的数据集上测试了这种方法,包括 goEmotions (28 种细粒度情感) 、tweetEmotion 和 tweetHate 。 他们使用了 FLAN-T5 和 DeBERTa 模型。
性能提升
结果显示了一个清晰的趋势: 对比分类优于标准分类,而 动态 \(\beta\) 方法通常产生最佳结果。
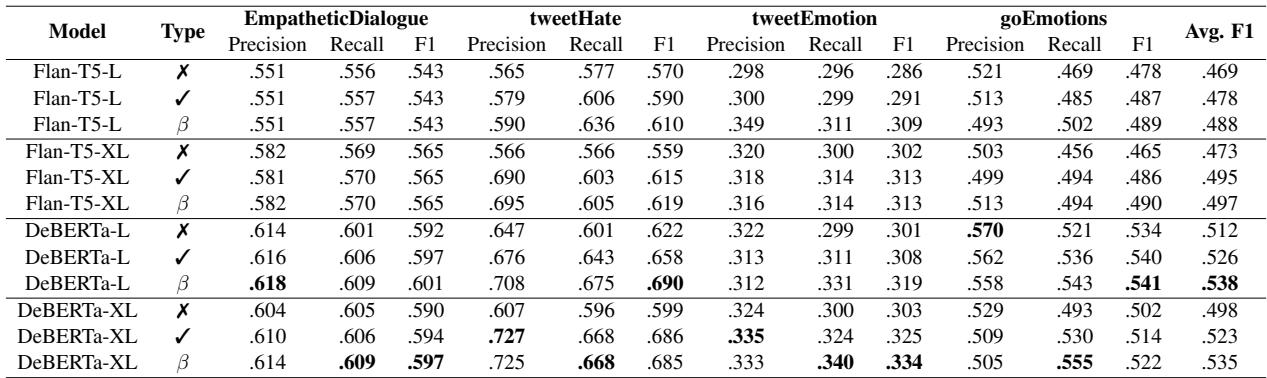
在表 1 中,注意最右侧的 Avg. F1 列。对于几乎所有模型 (FLAN-T5, DeBERTa) ,动态 \(\beta\) (标记为 \(\beta\)) 相比正常分类 (\(\pmb{x}\)) 或静态 beta (\(\checkmark\)) 取得了最高分。
进一步外推的效果
我们应该向“未来”看多远?作者尝试将目标层 \(\ell_t\) 设定得越来越远。
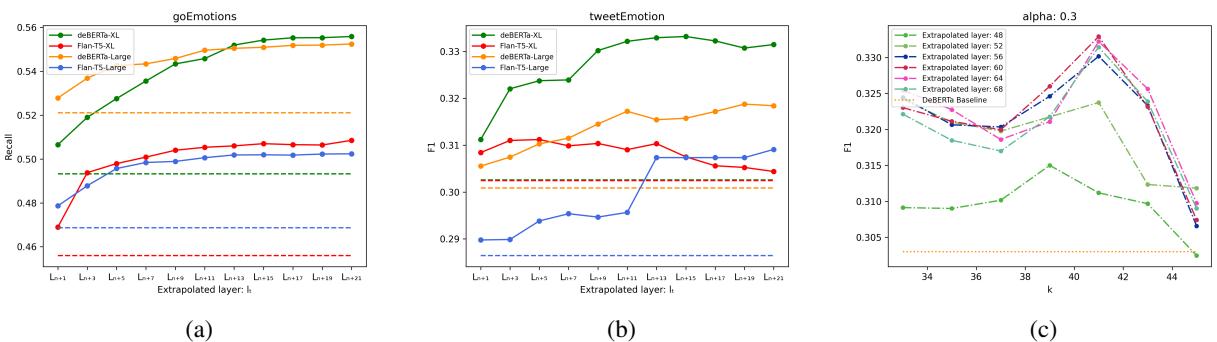
看图 2 中的 (a) , 我们可以看到对于 goEmotions 数据集,随着我们外推到更高的层 (在 x 轴上向右移动) ,召回率 (Recall) 提高了。这证实了假设: 模型在逐层移动的“方向”是正确的,沿着那条路径进一步推进会优化预测。
处理“中性”偏差
情感分类中最大的问题之一是模型喜欢打安全牌。当文本模棱两可时,它们经常默认为“中性”。
外推法迫使模型更有主见。因为“中性”的概率通常在各层之间保持平坦或下降,而特定情感 (如“好奇”或“反对”) 会上升,外推法放大了特定情感并抑制了中性情感。
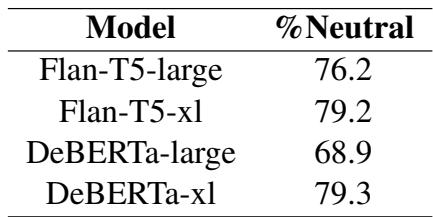
表 2 突出了这一成功。例如,使用 DeBERTa-xl,通过这种方法翻转的样本中,有近 80% 最初被 (错误地) 分类为中性。
定性示例
这在实践中看起来如何?该方法成功地将宽泛的情感细化为特定的情感。
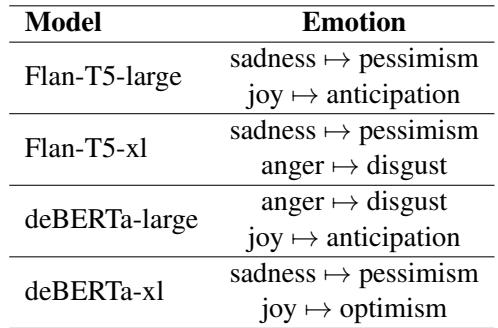
表 3 显示了常见的修正。模型经常从 悲伤 \(\rightarrow\) 悲观 或 快乐 \(\rightarrow\) 乐观 进行转变。模型并没有改变情感的极性 (正面/负面) ;它正在细化粒度。
我们可以从模型内部概率的热力图中看到这种演变:
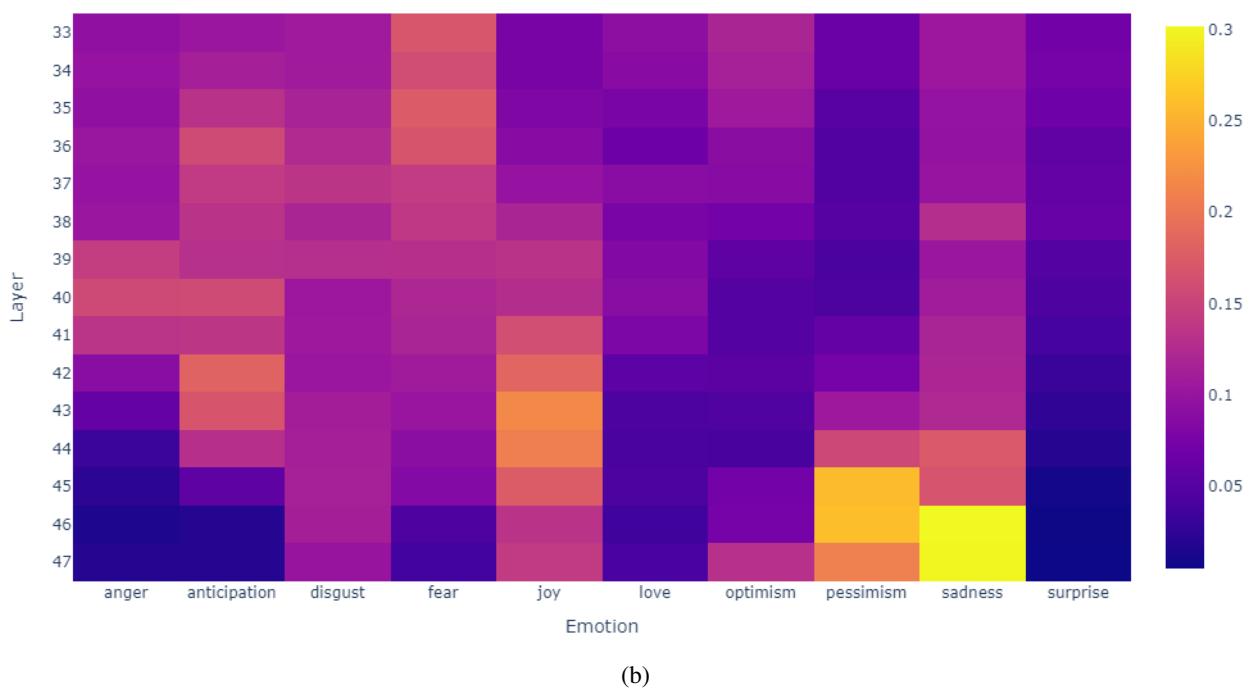
在上面的例子 (a) 中,注意“悲伤” (在该特定语境下的正确标签) 的概率在早期层的紫色区域开始很低,但在后期层变为明亮的黄色/橙色。线性外推利用这种上升趋势并将其投射到高置信度分数,从而锁定了正确的预测。
方法的稳定性
动态 \(\beta\) 方法的一个主要工程优势是稳定性。在标准的对比解码中,你必须选择一个超参数 \(k\) (作为业余者的最早层) 。如果你选错了 \(k\),性能就会崩溃。
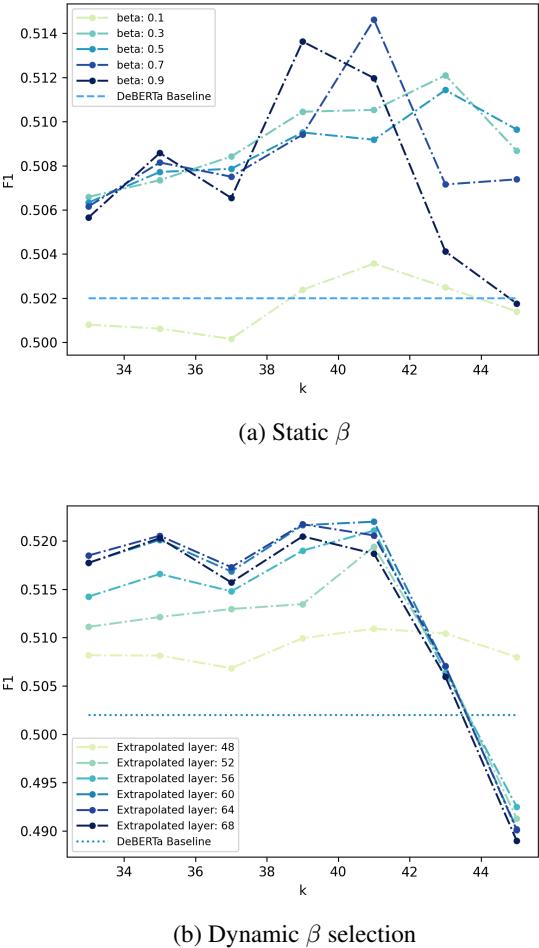
图 3 (上) 显示,使用静态 \(\beta\),F1 分数会随着 \(k\) 的变化而剧烈波动。然而,图 3 (下) 显示,使用 动态 \(\beta\) , 无论可用的候选层是哪些,性能 (彩色线) 都保持更加一致。这使得该方法在实际场景中更容易部署,而无需无休止的超参数调整。
结论
论文 “Linear Layer Extrapolation for Fine-Grained Emotion Classification” 提供了一种引人注目的新思路,让我们重新思考如何从大型语言模型中提取信息。
主要结论包括:
- 层即轨迹: 模型的层代表了从表面理解到深刻见解的旅程。
- 外推优于减法: 我们不应仅仅惩罚早期的错误,而应该向前投射模型的内部演变。
- 动态适应: 通过将对比惩罚与所选的特定层在数学上联系起来,我们可以创建一种鲁棒的、自适应的解码策略。
这种方法 不需要额外的训练——它只是从我们已有的模型中挖掘更多价值。它使我们能够揭开模型经常躲藏的“中性”安全毯,揭示真正反映人类交流的微妙、细粒度的情感。随着 LLM 继续融入社交/情感领域,像线性层外推这样的技术对于超越机械式的回答、迈向真正的共情和理解至关重要。