](https://deep-paper.org/en/paper/file-3322/images/cover.png)
引言
在大数据时代,文本信息的数量远超人类的阅读能力。为了从这些信息中理出头绪,我们需要依赖关系抽取 (Relation Extraction, RE) ——即教机器识别文本中实体之间关系的过程。例如,阅读“巴黎在法国”,并提取出三元组 (巴黎, 位于, 法国)。
这项技术是知识图谱、问答系统和语义搜索的基石。然而,当我们从简单的句子转向复杂的文档时,挑战呈指数级增长。 文档级关系抽取 (DocRE) 需要理解跨越长段落、涉及多个实体的连接。
问题在于: 训练这些模型需要海量的数据集,其中每一个可能的关系都必须被标注。在现实中,人类标注员会遗漏东西。他们可能标注了明显的关系,却漏掉了隐含的关系。这导致了不完整标注 (假阴性) ,即数据集告诉模型某个关系不存在,仅仅是因为它没有被标注出来。
既然数据是“残缺”的,我们该如何在不教会模型“残缺”思维的情况下训练它呢?
在近期一篇题为 “LogicST: A Logical Self-Training Framework for Document-Level Relation Extraction with Incomplete Annotations” 的论文中,研究人员提出了一个引人入胜的解决方案: 将深度学习的模式匹配能力与符号逻辑的严格推理相结合。他们推出了 LogicST , 这是一个在训练过程中使用逻辑规则作为诊断工具来“调试”模型预测的框架。
在这篇文章中,我们将深入探讨 LogicST 的工作原理,它如何利用逻辑来修复神经网络,以及为什么在这个特定任务上,它的表现甚至超过了像 GPT-4 这样的大型语言模型 (LLMs) 。
问题: 从不完整数据中学习
假阴性陷阱
想象一下,你参加了一场考试,老师仅仅因为没时间批改,就把你的一些正确答案判为错误。如果你根据这种反馈来学习,你就会停止给出那些正确的答案。
这正是 DocRE 中发生的事情。在一个包含 20 个实体的文档中,有近 400 个可能的配对。标注员几乎不可能仔细核实每一个配对。当数据集中包含未被标注的有效关系 (假阴性) 时,模型会被显式地训练为对它们预测“无关系”。这抑制了模型召回有效事实的能力。
自训练的局限性
对此常见的一个修复方法是自训练 (Self-Training) 。 在这种设置中,一个“教师”模型对数据进行预测。如果教师模型对某个在标注真值中缺失的关系非常确信,我们就假设教师是对的,并将其作为“伪标签”添加进去。然后,一个“学生”模型会基于这些新标签进行训练。
然而,自训练是有风险的。它受制于确认偏差 (Confirmation Bias) 。 如果教师模型犯了一个错误并且对此很自信,学生模型就会学习这个错误,在一个恶性循环中强化这个错误。此外,标准的自训练是“亚符号 (sub-symbolic) ”的——它关注统计模式,但并不理解其预测内容的逻辑含义。
解决方案: LogicST
LogicST 的作者提出了一个范式转变。我们不应该仅仅关注概率得分,而应该关注逻辑一致性 。
深度学习模型通常是“黑盒”——难以解释。相比之下,符号逻辑是严格且清晰的。如果模型预测 (A, 属于, B),逻辑规定它必须同时也接受 (B, 拥有部分, A)。如果模型预测了前者但否定了后者,我们就面临一个逻辑冲突 。
LogicST 使用这些规则作为诊断工具 。 通过识别冲突,该框架可以精准定位模型困惑的地方,并从数学上确定翻转标签 (从假变为真,反之亦然) 的最佳方式,以恢复逻辑的和谐。

如图 1 所示,如果模型预测歌曲“Have You Ever Been in Love”是专辑“One Heart”的*一部分 (part of) *,但同时声称“One Heart”*不包含 (does not have part) *这首歌,这就打破了一条逻辑规则。LogicST 识别出这一点并提出了一个“最小诊断”——即修复逻辑所需的最小改动。在这种情况下,将第二个陈述翻转为“真 (True) ”可以解决冲突并恢复一个缺失的标签。
方法论: 框架内部
LogicST 基于教师-学生 (Teacher-Student) 架构运行。让我们分解一下它的工作流程。
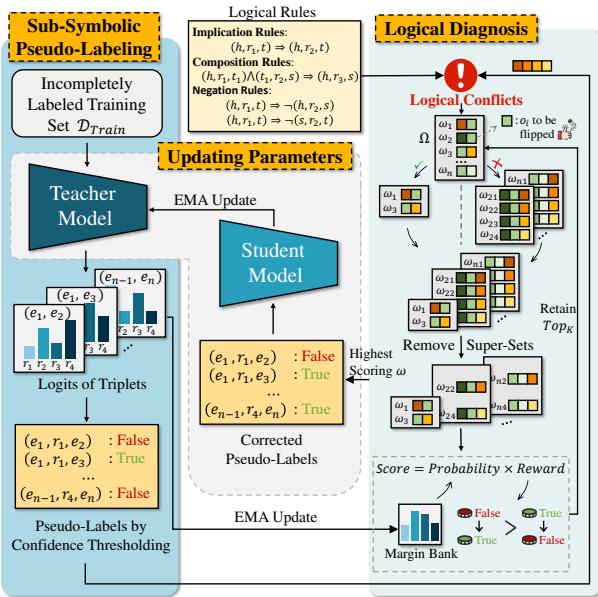
如图 2 所示,该过程包含三个主要阶段:
- 伪标注 (Pseudo-Labeling) : 教师模型预测训练文本中的关系。
- 逻辑诊断 (Logical Diagnosis) : 系统将这些预测与一组逻辑规则进行核对。如果发现冲突,它会计算修复冲突的最佳方案。
- 模型更新 (Model Update) : 学生模型基于这些经过逻辑修正的标签进行训练。然后教师模型会 (通过指数移动平均) 缓慢更新以匹配学生模型,如此循环往复。
1. 逻辑规则
研究人员定义了三种类型的一阶逻辑规则来约束抽取过程: 蕴涵 (Implication) 、组合 (Composition) 和否定 (Negation) 。
蕴涵规则意味着如果一个关系存在,另一个关系也必须存在。
 例子: 如果伦敦是英国的首都,那么伦敦一定位于英国。
例子: 如果伦敦是英国的首都,那么伦敦一定位于英国。
组合规则允许模型在实体之间跳转以推断新事实。
 例子: 如果巴黎是法国的首都,且法国位于欧洲,那么巴黎位于欧洲。
例子: 如果巴黎是法国的首都,且法国位于欧洲,那么巴黎位于欧洲。
否定规则防止互斥的关系同时出现。
 例子: 如果 X 是 Y 的配偶,那么 X 不可能是 Y 的父母。
例子: 如果 X 是 Y 的配偶,那么 X 不可能是 Y 的父母。
2. 诊断冲突
当教师模型生成伪标签时,LogicST 会根据上述规则检查它们。当预测集合 (\(\mathcal{O}\)) 与规则 (\(\mathcal{K}\)) 相互矛盾时,就会发生冲突 。
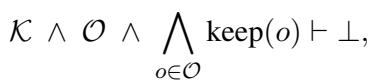
这里,\(\vdash \bot\) 意味着组合导致了矛盾。为了解决这个问题,系统寻找一个标签子集 (\(\omega\)) 进行“翻转” (将真变为假,反之亦然) ,从而消除矛盾 (\(\vdash \top\))。
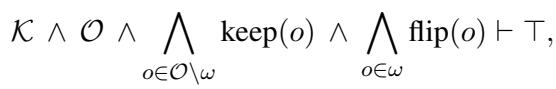
目标是最小诊断 (Minimal Diagnosis) : 找到使预测在逻辑上一致所需的最小改动次数。
3. 序列诊断: 选择最佳修复方案
通常,修复逻辑错误的方法不止一种。例如,如果 A 蕴涵 B,而我们有 A=真 和 B=假,我们可以让 B=真 或者 A=假。两者都能解决逻辑谜题,但哪一个在历史或事实上是正确的呢?
LogicST 使用一个评分函数来评估每一个潜在的诊断。分数基于两个因素: 概率和奖励 。
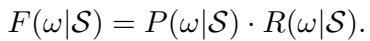
基于自适应阈值的概率
系统根据模型的置信度来计算诊断的概率。
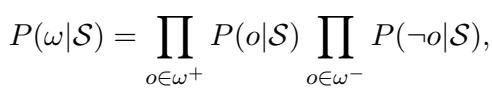
然而,简单的置信度分数是危险的,因为神经网络对“流行”类别有偏见 (例如,“位于”很常见,“是…的作者”很罕见) 。为了解决这个问题,LogicST 使用了一个间隔库 (Margin Bank) 。
间隔库跟踪模型随时间推移在不同类别上的表现。它计算一个动态间隔:
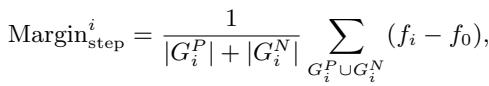
然后,它利用这个间隔来调整概率计算,有效地给罕见类别提供“补偿”,使它们不被忽略。
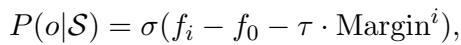
发现奖励
在训练的早期阶段,模型往往具有高精确率但低召回率 (它遗漏了很多事实) 。因此,LogicST 激励“正向翻转”——将标签从假变为真——以恢复那些缺失的标注。
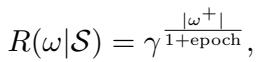
随着模型改进,这个奖励函数会随时间衰减,将重心从发现转移到准确性。
实验与结果
研究人员在 DocRED 和 DWIE 等主要基准上测试了 LogicST。他们将其与原版 BERT 模型、其他自训练方法 (如 CAST) 甚至大型语言模型进行了比较。
在不完整数据上的表现
最引人注目的结果之一来自 Re-DocRED 数据集 (DocRED 的修正标注版本) 。
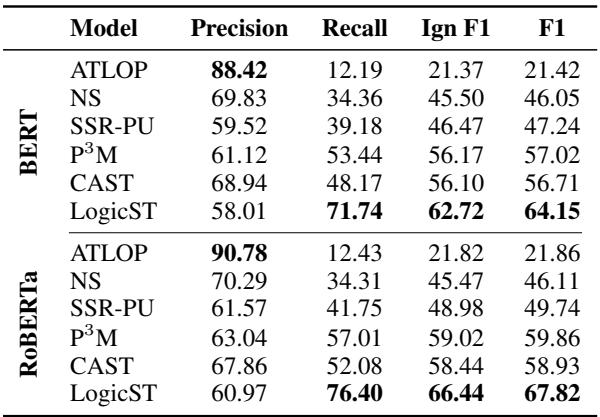
在表 2 中,我们看到了在“极度无标签”设置下的结果。LogicST 显著优于骨干模型 (ATLOP) 和之前的最先进方法 (如 P\(^3\)M 和 CAST) 。召回率的跃升 (从约 50% 到约 76%) 凸显了 LogicST 能够发现其他模型错过的“大海捞针”般的信息。
优于 LLMs?
有趣的是,论文将 LogicST 与 GPT-3.5 和 GPT-4 (使用少样本学习) 进行了比较。
虽然 LLMs 是强大的通才,但在这一特定任务上 LogicST 表现更佳。例如,在 Re-DocRED 测试集上, LogicST 达到了 69.26% 的 F1 分数 , 而 GPT-4 (1-shot) 仅达到 27.75% 。 这表明,对于像文档关系抽取这样专业的、高精度的任务,一个经过符号逻辑和严格约束训练的小型模型往往优于通用型的 LLM。
对数据稀缺的鲁棒性
当正样本稀缺时,LogicST 同样表现出色。
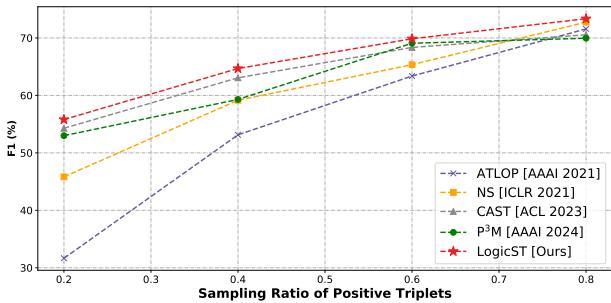
图 3 显示,当我们减少已标注正样本三元组的数量 (在 X 轴上向左移动) 时,LogicST (红线) 的性能下降速度比其他方法慢得多。即使只有 20% 的数据被标注,它仍保持了高性能,证明逻辑规则有效地填补了人类标注员留下的空白。
处理长距离依赖
文档级抽取最难的部分之一是连接文本中相距甚远的实体。
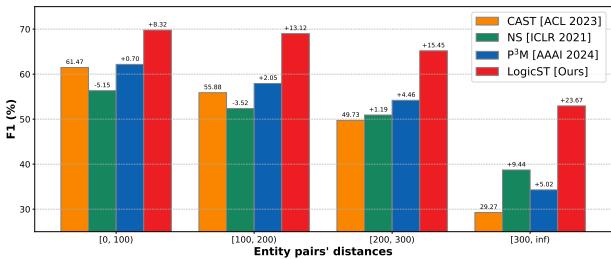
图 4 根据实体对之间的距离对性能进行了分组。随着距离的增加,LogicST 的优势变大。为什么?因为逻辑与距离无关。如果 A 蕴涵 B,无论 A 和 B 是在同一个句子里还是相隔三个段落,这都不重要。符号推理弥补了神经注意力机制可能错过的差距。
案例研究: 逻辑实战
为了直观地展示 LogicST 如何工作,让我们看一个研究中涉及歌手席琳·迪翁 (Celine Dion) 的真实例子。

在图 6 中,基线模型正确识别出歌曲“Have You Ever Been in Love”是专辑“One Heart”的*一部分 (part of) *。然而,它未能预测出反向关系: 即“One Heart”*包含 (has part) *这首歌。
这造成了逻辑冲突。 序列诊断模块检测到了对规则 \((h, \text{part of}, t) \Leftrightarrow (t, \text{has part}, h)\) 的违反。它评估了概率并确定最可能的修复方法是将缺失的关系翻转为“真”。结果是一个更完整且一致的知识图谱。
效率
最后,复杂的框架往往伴随着沉重的计算成本。然而,LogicST 却出奇地高效。
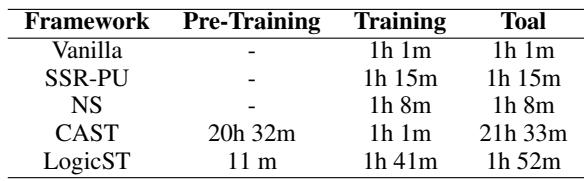
表 4 显示 LogicST 比其主要竞争对手 CAST 快得多。CAST 需要超过 20 小时的预训练,而 LogicST 在 2 小时内就完成了整个流程。这是因为 LogicST 不需要多轮复杂的重新训练;逻辑诊断是在循环中高效完成的。
结论
LogicST 代表了 神经符号 AI (Neuro-Symbolic AI) 向前迈出的有力一步。它承认虽然深度学习擅长从文本中学习表征,但它缺乏人类推理的内在结构。通过将显式的逻辑规则注入训练循环,作者实现了:
- 在文档级关系抽取上达到了SOTA (最先进) 性能 。
- 更高的召回率 , 成功在不完整数据集中恢复了缺失的标注。
- 可解释性 , 因为模型的每一次修正都可以追溯到一条特定的逻辑规则。
对于学生和研究人员来说,LogicST 是一个很好的例子,说明我们并不总是需要“更大”的模型。有时,我们需要仅仅是能够更具逻辑地“思考”的模型。