](https://deep-paper.org/en/paper/file-3326/images/cover.png)
通用人工智能 (AGI) 的梦想在很大程度上取决于机器能否像人类一样处理信息: 即以多模态的方式。当你看着一张拥挤街道的照片并回答“现在过马路安全吗?”这个问题时,你正在无缝地融合视觉感知与语言推理能力。像 LLaVA 和 Flamingo 这样的多模态大语言模型 (MLLM) 在模仿这种能力方面已经取得了巨大进步。
然而,这里有个问题。随着这些模型的参数量增长到数十亿,让它们适应新任务的成本变得极其昂贵。传统的“全量微调”——即更新模型中的每一个权重——不仅计算量巨大,而且对存储空间的要求也极高。
这就引出了一个关键问题: 我们能否通过仅更新极小一部分参数,在不牺牲性能的情况下,使这些巨大的多模态模型适应新任务?
来自罗切斯特理工学院、Meta AI 等机构的研究人员在他们的论文 M\(^2\)PT: Multimodal Prompt Tuning for Zero-shot Instruction Learning 中给出了肯定的回答。他们引入了一种方法,仅微调模型 0.09% 的参数,就能达到与全量微调相当、甚至有时更好的效果。
挑战: 单模态陷阱
为了解决微调成本的问题,该领域转向了 参数高效微调 (PEFT) 。 像 LoRA (低秩适应) 和 提示微调 (Prompt Tuning) 等技术已成为标准配置。具体来说,提示微调涉及冻结整个预训练模型,仅训练一小组添加到输入中的“软提示” (soft prompts,即向量)。
虽然有效,但大多数现有的提示微调方法都存在“单模态”偏差。它们倾向于:
- 仅向语言模型添加提示 (忽略视觉编码器) 。
- 仅向视觉编码器添加提示 (忽略语言模型) 。
这种脱节的方法忽视了视觉和文本之间复杂的相互作用。M\(^2\)PT 背后的研究人员认为,要真正掌握零样本指令学习,我们需要一种统一的方法,同时引导模型的“眼睛” (视觉编码器) 和“大脑” (LLM) 。
M\(^2\)PT 登场: 多模态提示微调
这篇论文的核心创新在于一种分层架构,它将可学习的提示同时插入到模型的视觉和语言组件中,并通过一个专门的交互层将它们连接起来。
架构概览
让我们拆解一下这个架构。一个标准的多模态大语言模型 (MLLM) 包含处理图像的 视觉编码器 (Vision Encoder,如 CLIP) 和处理文本并生成答案的 大语言模型 (LLM,如 Vicuna/LLaMA)。
M\(^2\)PT 引入了三个特定的可调组件,同时保持其余庞大模型的参数冻结:
- 视觉提示 (\(P_v\)): 插入到视觉编码器中的可学习向量。
- 文本提示 (\(P_t\)): 插入到 LLM 中的可学习向量。
- 跨模态交互: 将视觉特征与文本空间对齐的层。
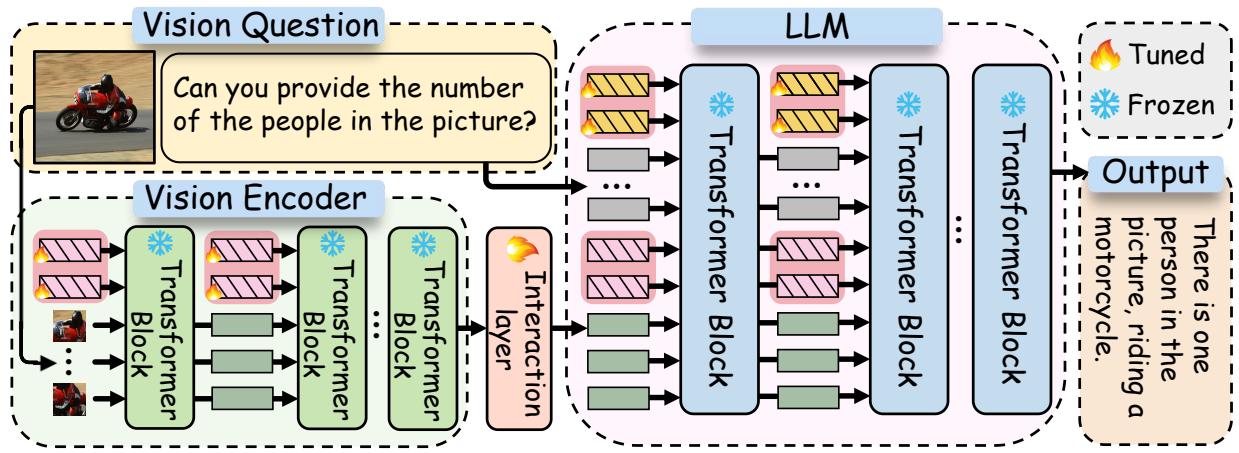
如 图 2 所示,工作流程非常优雅。视觉提示帮助编码器提取与任务相关的视觉特征。然后,这些特征通过交互层投射出去,与 LLM 内部的文本提示进行“对话”。这确保了语言模型接收到的不仅仅是原始图像数据,而是已经与文本指令对齐的、经过视觉提示引导的数据。
1. 视觉提示
研究人员将一组可调向量 (\(P_v\)) 插入到视觉编码器 (\(f_v\)) 的层中。这些提示被放置在每一层序列的开头。
在数学上,对于视觉编码器的第 \(i\) 层,输出 \(O_v^i\) 是通过处理提示和上一层的输出来计算的:
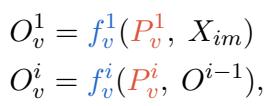
这使得视觉编码器能够在不改变其原始预训练权重的情况下,专门针对手头的任务调整其特征提取过程。
2. 文本提示
同样地,文本提示 (\(P_t\)) 被插入到 LLM 中。然而,这些不仅仅是标准的 NLP 提示。由于它们在多模态上下文中运行,它们需要捕捉图像和文本之间的语义关系。
LLM 层的输出 (\(O_m\)) 是通过处理文本提示、对齐后的视觉信息以及文本嵌入 (\(O_t\)) 得出的。
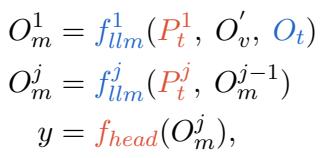
3. 核心奥秘: 跨模态交互
M\(^2\)PT 最显著的特点是它如何处理视觉和文本之间的交接。对于细粒度任务,简单地将视觉输出馈送给 LLM 往往是不够的。
研究人员引入了一个可调的 交互层 (\(f_{in}\))。该层获取视觉编码器的输出 (\(O_v^N\)),并将其线性投影到文本嵌入空间中。
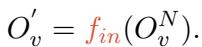
这种投影确保了模型的“视觉思维”被转化为一种 LLM 的文本提示可以理解并有效交互的“语言”。
为什么这行得通: 探究“黑盒”内部
你可能会想: 模型实际上真的在使用这些提示吗,还是说它们只是噪音?研究人员可视化了模型的注意力激活图,以观察其计算能量集中在哪里。
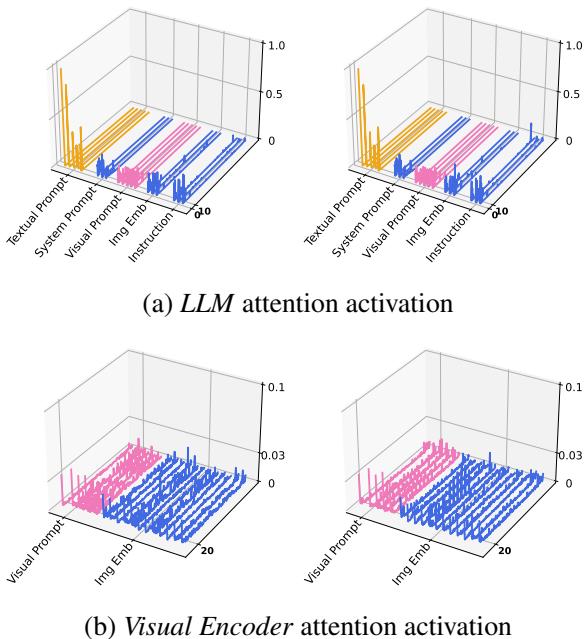
图 3揭示了一些迷人的现象:
- 在 LLM 中 (图 3a): 对应于文本提示区域有很高的激活峰值。
- 在视觉编码器中 (图 3b): 视觉提示的激活明显高于大多数其他标记 (token)。
这证实了冻结的骨干网络正在积极地关注这些学习到的提示,以指导其推理。这些提示就像“灯塔”一样,指引庞大的预训练网络在零样本任务中走上正确的推理路径。
实验结果
研究人员在广泛的基准测试上评估了 M\(^2\)PT,包括综合性的 MME 基准、VSR (视觉空间推理) 以及像 CIFAR-10 和 MNIST 这样的标准感知任务。他们将该方法与 LoRA (低秩适应) 和 VPT (视觉提示微调) 等最先进的 PEFT 方法进行了比较。
以最少的参数实现卓越的性能
结果令人印象深刻。M\(^2\)PT 在各项指标上始终优于其他参数高效的方法。
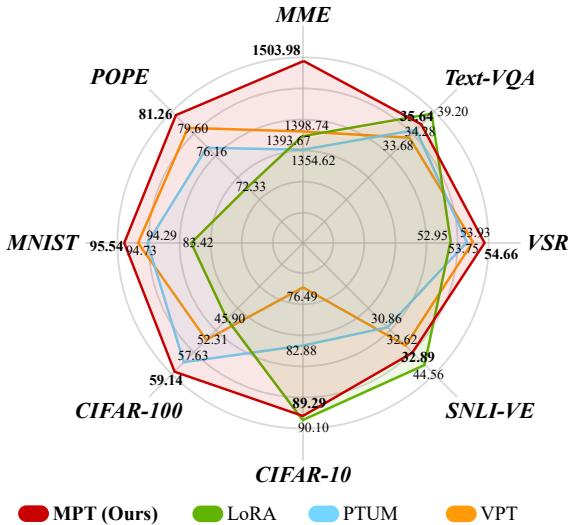
如上方的雷达图 (图 1) 所示,M\(^2\)PT (由蓝线表示) 在几乎所有数据集上都包围了基线方法。它在测试感知和认知能力的 MME 基准测试中表现尤为强劲。
让我们看看硬数据:
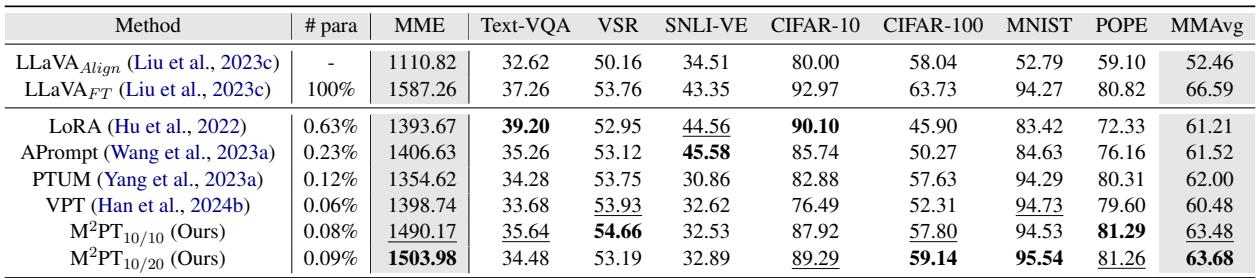
表 1 突显了效率:
- LoRA 微调了 0.63% 的参数。
- M\(^2\)PT 仅微调了 0.09% 的参数。
尽管使用的参数比 LoRA 少了近 7 倍 , M\(^2\)PT 却取得了更高的平均分 (MMAvg) 63.68 , 而 LoRA 为 61.21。事实上,在 VSR、MNIST 和 POPE 等数据集上,M\(^2\)PT 甚至优于 全量微调的 LLaVA 模型 (更新 100% 的权重)。这表明对于某些零样本任务,全量微调实际上可能导致过拟合或灾难性遗忘,而提示微调能更好地保留模型的通用能力。
组件分析: 我们需要所有这些吗?
同时使用视觉和文本提示的复杂性是必要的吗?我们能不能只用一种?
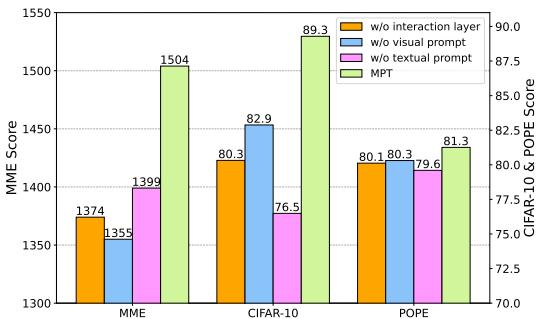
图 4 展示了一项消融实验,研究人员逐一移除了组件。
- 不带交互层 (橙色): 性能显著下降,证明仅仅有提示是不够的;它们需要对齐。
- 不带视觉提示 (蓝色) & 不带文本提示 (粉色): 移除任何一种模态的提示都会损害性能。
有趣的是,重要性因任务而异。对于 MME (一个复杂的多模态任务),视觉提示至关重要。对于 CIFAR-10 (一个分类任务),文本提示发挥了更大的作用。这验证了包含两者以处理各种任务的设计选择。
定性成功案例
数字固然好,但这如何转化为实际的模型行为呢?

图 8 展示了 M\(^2\)PT 成功而其他方法失败的具体例子。
- MME 示例 (上): 问题询问图中是否有椅子。图片显示人们在地上通过一张棋盘下棋,背景中有椅子。像 PTUM 和 VPT 这样的基线模型回答“No”,可能只关注了人或棋盘。M\(^2\)PT 正确地发现了椅子并回答“Yes”,展示了卓越的视觉感知能力。
- CIFAR-10 示例 (下): 图片是一张模糊的猫的照片。其他模型产生了幻觉,认为是“卡车”或“飞机”。M\(^2\)PT 正确识别为“猫”,显示了即使在低质量视觉输入下的鲁棒性。
结论与未来影响
M\(^2\)PT 论文为高效 AI 适应的未来提出了令人信服的论据。通过策略性地在模型的视觉和语言组件中放置可学习的提示,并确保它们可以通过交互层进行通信,我们可以在几乎可以忽略不计的参数成本下实现最先进的性能。
给学生和从业者的主要启示:
- 模态协同: 在微调过程中分别处理视觉和语言并非最佳方案。它们必须对齐。
- 效率是关键: 你不需要重新训练一个 70 亿或 130 亿参数的模型来教它新技巧。如果是正确的参数,0.09% 的参数量往往就足够了。
- 零样本潜力: 经过适当调整的提示使模型能够有效地泛化到未见过的任务,这是现实世界 AI 助手的一项关键能力。
随着 MLLM 规模的不断扩大,像 M\(^2\)PT 这样的方法很可能成为在消费级硬件上部署专用模型的标准,从而使强大的多模态 AI 的使用更加普及。