](https://deep-paper.org/en/paper/file-3327/images/cover.png)
在信息过载的时代,验证单个声明往往感觉像是在做侦探工作。你读了一个标题,查阅了一篇新闻文章,观看了一段视频剪辑,或许还看了一眼图片说明。很少有单一文档能包含所有答案。然而,如今大多数自动事实核查系统都在“闭门造车”: 它们只查看一段文本,然后输出二元的“真”或“假”。
但错误信息很少是非黑即白的。一个声明可能大部分是真实的,但包含一个捏造的统计数据。或者,它可能描述了一个真实事件,但将其归因于视频中显示的错误地点。为了建立信任,人工智能不仅需要标记帖子,还需要解释声明中究竟哪一部分与证据相矛盾。
这引出了 M3D , 这是最近一篇研究论文中介绍的一种新颖框架,旨在解决多模态( MultiModal) 、多文档( MultiDocument) 的细粒度不一致性检测问题。本文将探讨研究人员如何创建一个能够解析文本、图像、视频和音频的系统,以精确定位复杂声明中的特定逻辑错误。
问题: 事实核查的“黑盒”
当前最先进的错误信息检测面临三个明显的局限性:
- 单源偏差 (Single-Source Bias) : 大多数模型假设所有证据都来自一个文档。实际上,验证突发新闻事件通常需要综合视频报道、目击者音频片段和书面文章。
- “中立”盲区 (The “Neutral” Blind Spot) : 现有模型难以处理模棱两可的情况。如果证据无法验证某个声明,模型往往会强行预测为“假”,而不是承认“中立” (信息不足) 。
- 缺乏粒度 (Lack of Granularity) : 将一个复杂的句子标记为“假”并没有太大帮助。用户需要知道具体是哪个实体、动作或关系是不正确的。
M3D 方法提出了一个解决方案: 针对一组多模态来源,预测声明中每一部分的逻辑关系 (蕴含、中立或矛盾) 。
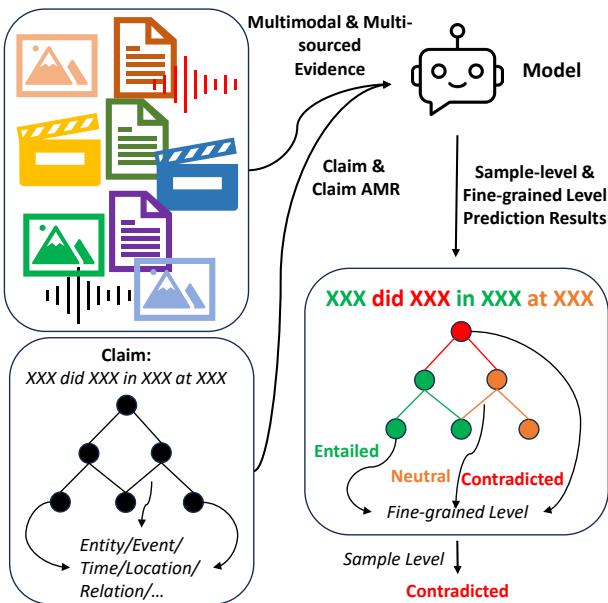
如图 1 所示,其目标是获取一个声明并将其分解为语义图。然后,模型针对证据检查每个节点 (对象/实体) 和元组 (关系) ,从而生成详细的真实性地图。
基础: 构建 M3DC 数据集
训练细粒度事实核查模型的最大障碍之一是缺乏数据。简直没有一个数据集能为需要跨文档、多模态推理的声明提供细粒度标签。研究人员通过合成他们自己的基准测试集解决了这个问题,称为 M3DC 。
第一步: 构建多模态知识图谱
该过程始于 “NewsStories”,这是一个包含文章、图像和视频的新闻聚类集合。研究人员并没有直接将这些数据丢进模型;他们使用 抽象语义表示 (AMR) 对其进行了结构化。
AMR 将句子的逻辑 (谁对谁做了什么) 捕获为一个图。通过从文本、图像说明和视频摘要中提取 AMR 树,然后使用共指消解 (例如,弄清楚文本中的“火灾”与视频中的“火焰”是同一事物) 将它们链接起来,他们构建了一个统一的知识图谱 (KG)。
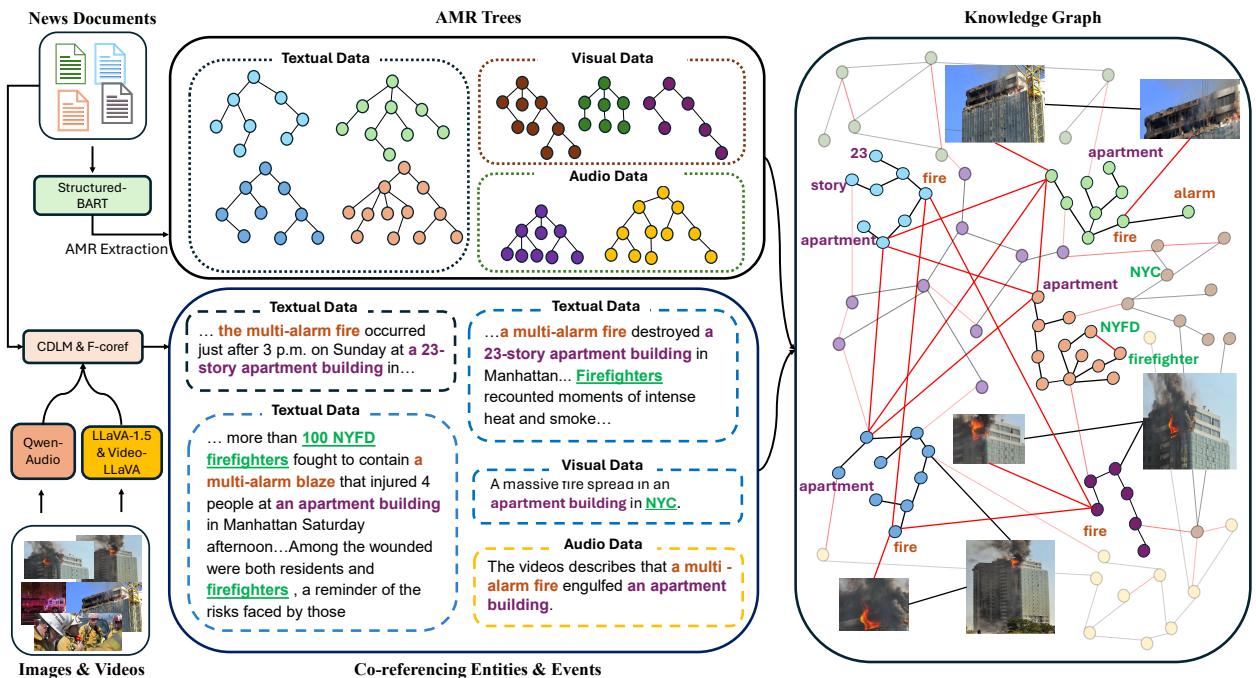
图 2 展示了这一构建过程。请注意文本数据、视觉数据 (由 LLaVA 处理) 和音频数据 (由 Qwen-Audio 处理) 是如何汇聚的。这个跨媒体图谱充当了事件的“基准真相”。
第二步: 生成和篡改声明
拥有了强大的知识图谱后,下一步是生成声明来训练模型。
- 遍历图谱: 系统遍历 KG 以选择相连的事实 (知识元素) ,并使用语言模型生成一个 真实 (蕴含) 的声明。
- 声明篡改: 这是巧妙的部分。为了教模型识别谎言和歧义,研究人员使用了一个“声明篡改”模型。该模型获取真实的声明和证据,然后扰动声明使其变为 中立 或 矛盾 。
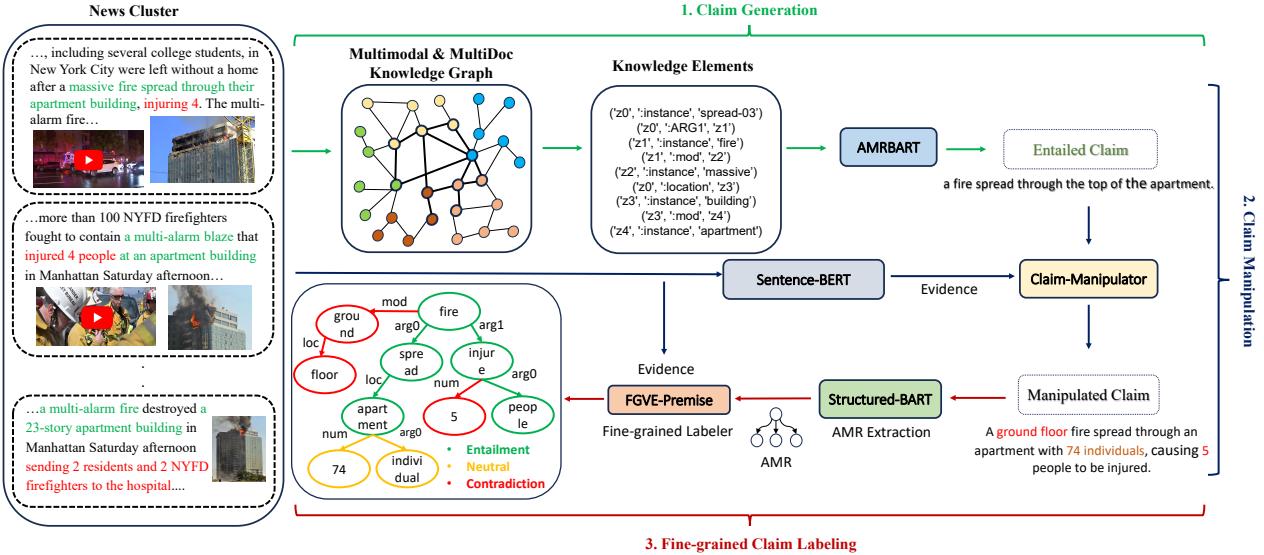
如图 3 所示,篡改器可能会将“火势蔓延至顶部”改为“火势蔓延至底层” (矛盾) ,或者添加未经验证的细节,如“74 人” (中立) 。
为了确保高质量的篡改,研究人员使用强化学习 (RL) 训练了篡改器。他们使用了一个奖励函数来平衡三个目标:
- 达到目标标签 (例如,强制产生矛盾) 。
- 保持文本与原始声明相似 (使用 ROUGE 分数) 。
- 保持逻辑一致性。
奖励函数的数学定义如下:
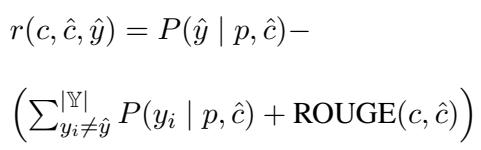
在这里,如果生成的声明 \(\hat{c}\) 与目标标签 \(\hat{y}\) 匹配,同时在文本上保持与原始声明 \(c\) 接近,模型就会获得奖励。为了防止 RL 模型偏离流畅的语言太远,他们使用了带有 KL 散度惩罚的近端策略优化 (PPO):
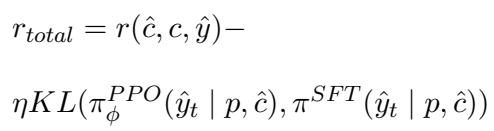
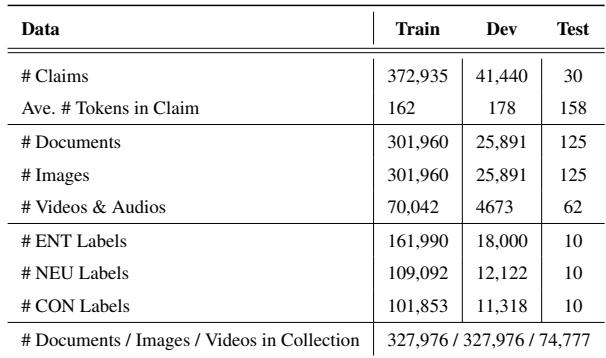
这一严格的过程产生了一个庞大的数据集。下方的 表 1 强调了 M3DC 与现有数据集的对比——它是唯一一个在多模态、多文档设置中提供细粒度标签的数据集。

数据集的规模令人印象深刻,涵盖了 15,000 个主题下的超过 400,000 条声明。
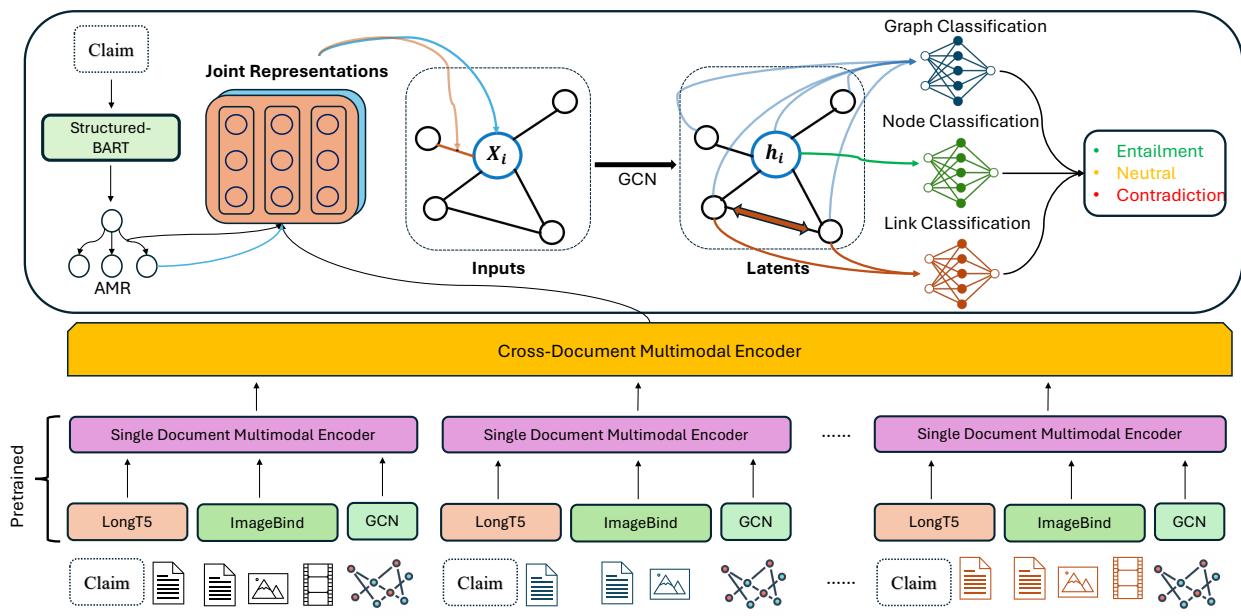
M3D 模型架构
如何构建一个既能“阅读”文本图谱又能同时“观看”视频的神经网络?M3D 模型采用分层方法,结合了多模态编码器和图卷积网络 (GCN)。
1. 多模态编码
该模型保留了证据的上下文。
- 文本: 使用 LongT5 编码,能够处理跨多个文档的长文本序列。
- 视觉/音频: 使用 ImageBind 编码,它将图像、视频和音频映射到一个共享的嵌入空间。
- 知识图谱: 特定聚类的 KG 使用 GCN 进行编码。
这些表示被串联起来,形成了证据的丰富联合表示。
2. 图推理
核心推理发生在声明的 AMR 图上。模型使用多模态特征初始化图节点,然后使用 GCN 更新它们。这允许信息在声明的逻辑结构中传播。
节点特征更新规则为:
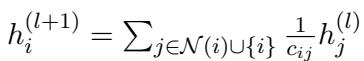
这个方程本质上是说,一个节点的理解 (\(h_i\)) 是通过对其邻居的特征 (\(h_j\)) 进行平均来更新的。
至关重要的是,模型还更新边特征 , 认识到两个词之间的关系 (例如,“导致”) 与词本身同样重要。
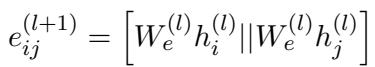
3. 预测
最后,模型使用这些丰富的图特征在两个层面上进行预测:
- 样本级: 整个声明是真、假还是中立?
- 细粒度级: 这个特定的节点或边是蕴含、矛盾还是中立?
实验结果
研究人员将 M3D 与几个强大的基线进行了评估,包括像 LLaVA-1.5 和 MiniGPT-v2 这样的大型视觉-语言模型 (LVLM)。
在 M3DC 上的表现
在他们自己的基准测试中,M3D 表现出了卓越的性能,特别是在区分“中立”声明方面——这是标准 LVLM 众所周知的弱点,因为它们往往过度自信。
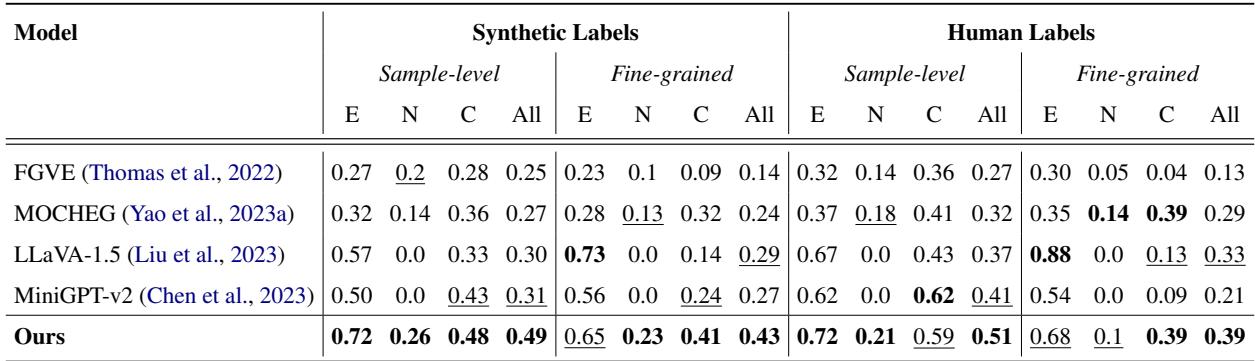
如表 3 所示,与基线相比,M3D 在中立 (N) 和矛盾 (C) 类别上取得了显著更高的 F1 分数。
泛化到其他数据集
为了证明他们的模型不仅仅是过拟合了自己的数据,他们在 MOCHEG 数据集上进行了零样本 (无需重新训练) 测试。
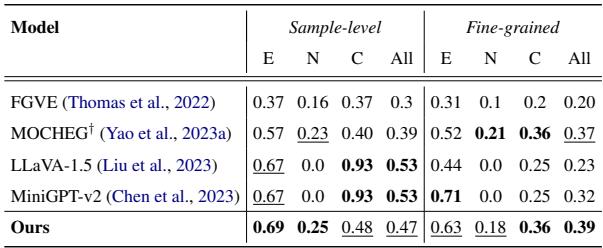
表 4 显示,M3D 在细粒度准确性方面优于 LLaVA-1.5 等最先进的模型。虽然一些 LVLM 在样本级预测上得分较高,但它们未能有效处理中立情况,往往在不确定时随机猜测或默认为“矛盾”。
定性分析: 看见逻辑
M3D 的强大之处最好通过视觉来理解。在下面的例子中,模型分析了一个关于“政府大楼”遭到袭击的声明。
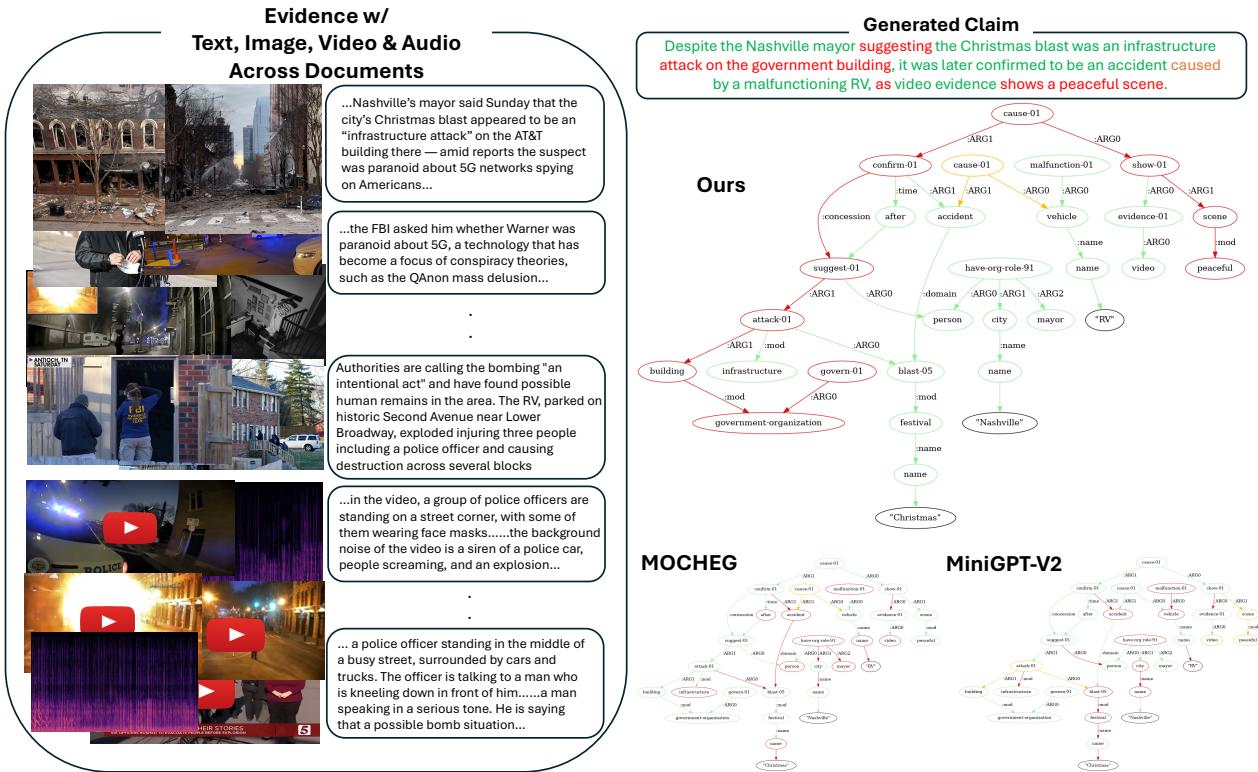
在图 5 中,请看“Ours” (M3D) 生成的图。它正确地识别出指代“政府大楼”的特定节点是矛盾的 (红色) , 因为证据 (文本和音频) 证实那是 AT&T 大楼。它还识别出“警笛声”的音频证据与“平静的场景”这一声明相矛盾。相比之下,像 MOCHEG 或 MiniGPT-v2 这样的基线模型无法生成连贯的图或识别具体的错误。
这是另一个细粒度预测的例子:
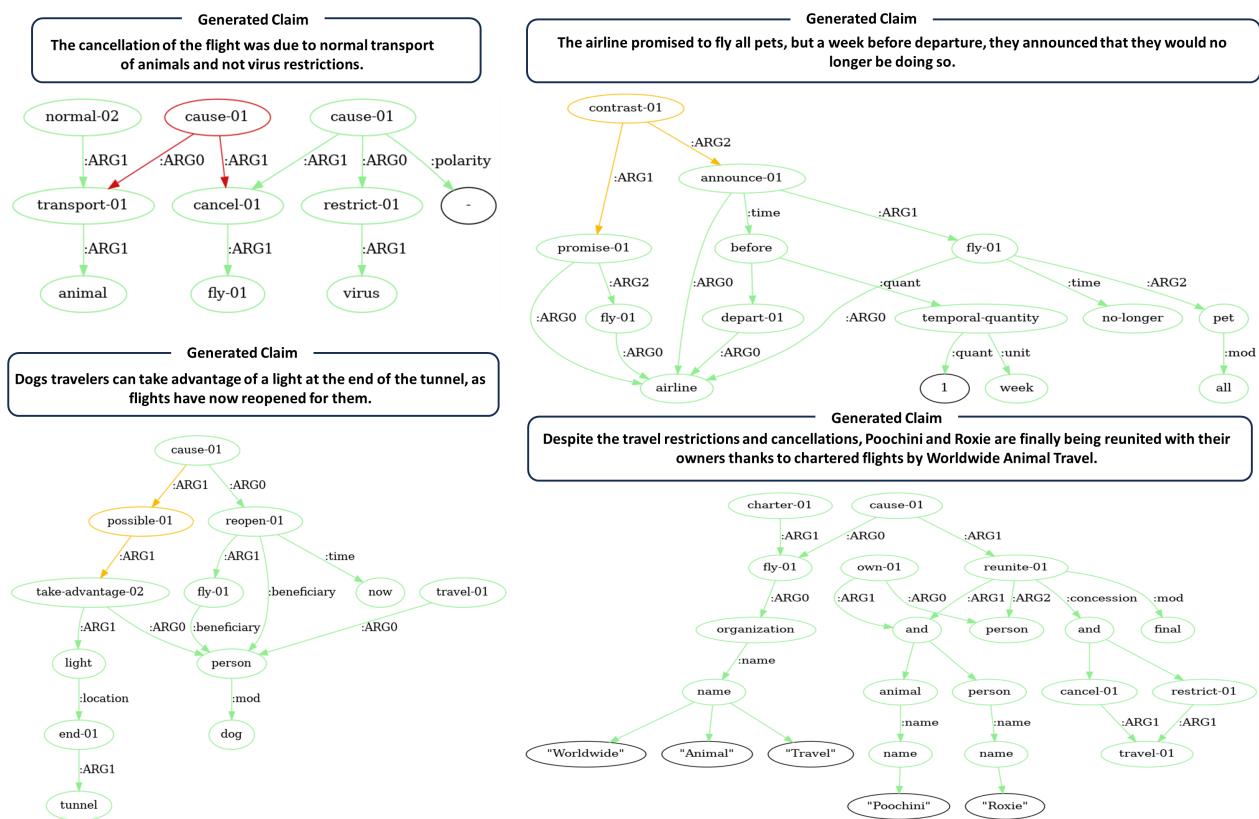
在图 8 (左上角) 中,模型正确地识别了关于航班取消的矛盾,将因果链接标记为“假” (红色) 。
多模态重要吗?
研究人员进行了一项消融研究,以查看哪些数据类型对性能贡献最大。
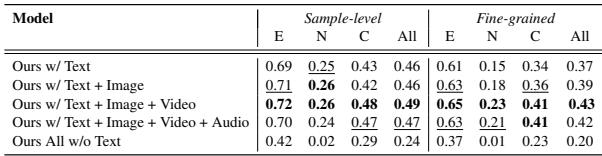
有趣的是, 表 5 显示移除文本会导致性能下降最大。这在新闻验证中是意料之中的,因为核心叙事通常是文本形式的。然而,当存在所有模态 (文本 + 图像 + 视频 + 音频) 时,性能最佳,这证明该模型成功整合了跨模态线索以完善其判断。
该数据集包含许多视觉证据至关重要的例子。例如,在下方的图 7 中,验证破坏程度或涉及的具体设备很大程度上依赖于结合报道解读图像。

结论
M3D 框架代表了自动事实核查向前迈出的重要一步。通过摆脱二元的“真/假”标记,转向细粒度的多模态分析,它为验证信息提供了一种更透明、更实用的工具。
主要收获:
- 粒度是关键: 用户从知道哪里错了中获益,而不仅仅是知道有些东西错了。
- 多模态至关重要: 现实世界的声明跨越文本、视频和音频。忽略任何模态都会导致盲区。
- 合成很重要: M3DC 数据集的创建流程展示了一种为复杂推理任务生成高质量训练数据的强大方法。
随着生成式 AI 继续模糊事实与虚构之间的界限,像 M3D 这样能够对照证据网络剖析声明逻辑的系统,对于维护数字生态系统中的信任至关重要。