](https://deep-paper.org/en/paper/file-3330/images/cover.png)
那是谁?利用匹配增强推理解决多模态大模型的身份识别危机
像 GPT-4V 和 LLaVA 这样的多模态大语言模型 (MLLMs) 已经彻底改变了计算机与世界交互的方式。你可以上传一张复杂场景的照片,这些模型就能描述光线,阅读标志上的文字,或者告诉你照片里是什么品种的狗。这感觉简直像魔法一样。
然而,当你问一个非常具体、以人为中心的问题时,这种魔法往往会消失: “红框里的这个人是谁?”
除非这个人是全球知名的名人或政治家,否则 MLLMs 经常会失败。它们可能会产生幻觉编造一个名字,简单地说“我不知道”,或者由于隐私保护机制而完全拒绝回答。这个具体的挑战被称为基于视觉的实体问答 (Visual-based Entity Question Answering, VEQA) 。
在这篇文章中,我们将深入探讨一篇名为 《MAR: Matching-Augmented Reasoning for Enhancing Visual-based Entity Question Answering》 (MAR: 用于增强基于视觉的实体问答的匹配增强推理) 的研究论文。研究人员提出了一个巧妙的解决方案,不再只是简单地要求模型“再仔细看看”。相反,他们引入了一个系统来构建一个证据网络——即匹配图 (Matching Graph) ——以帮助模型准确识别特定人物,即使这些人并不出名。
问题所在: 为什么 MLLMs 在身份识别上举步维艰
要理解为什么 VEQA 如此困难,我们需要看看 MLLMs 是如何处理图像的。它们依赖于训练数据。如果一个人在训练数据中出现了数百万次 (比如美国总统) ,模型就能认出他们。如果这个人是当地的外交官或特定的记者,模型很可能对他们的身份一无所知。
此外,像 GPT-4V 这样的商业模型有严格的安全策略。即使模型在统计上能够猜出某人是谁,它通常也会触发拒绝响应——“我不能识别现实中的人”——以保护隐私。
下图完美地展示了这些场景:

让我们分解一下 图 1 :
- 场景 (a): 理想路径。 模型看到一张王毅 (中国外交部长) 的照片。标题明确提到了他的名字。当被问到“他是谁?”时,模型结合红框的视觉信息和标题中的文本,给出了正确的回答。这是 MLLMs 表现最好的时候。
- 场景 (b): 失败案例。 这里我们看到一张习近平和唐纳德·特朗普的照片。然而,用户询问的是红框中的特定人物,假设标题很模糊或者模型的安全过滤器被触发。尽管视觉信息对人类来说很清晰,但模型拒绝回答或无法识别他们。
- 场景 (c): MAR 解决方案。 这就是我们要探讨的内容。该系统不仅仅查看单张图像。它会查看其他图像的数据库。它找到了一个匹配项——“嘿,这张新照片里的脸看起来和另一张照片里的脸一模一样,而那张照片我们确实知道名字是王毅。”它通过连接这些线索来回答问题。
解决方案: 匹配增强推理 (MAR)
这篇论文的核心见解是: 识别不应仅依赖于模型的内部记忆。 相反,我们应该将身份识别视为一个检索问题。如果我们有一个包含新闻图片和标题的大型数据库 (一个“数据湖”) ,我们就可以利用这些外部知识来识别新查询中的人物。
作者提出了 MAR (匹配增强推理) 。 MAR 不仅仅是检索相似的图像,它还构建了一个 匹配图 (Matching Graph) 。 这个图谱映射了不同文档中人脸和名字之间的关系,为 MLLM 提供了一个结构化的“作弊条”来进行推理。
架构: 从粗粒度到细粒度
要理解 MAR 为何独特,我们需要将其与现有的检索方法进行比较。标准的检索增强生成 (RAG) 通常在“粗粒度”层面工作——它检索整个文档。MAR 则在“细粒度”层面工作——它检索特定的人脸和名字。
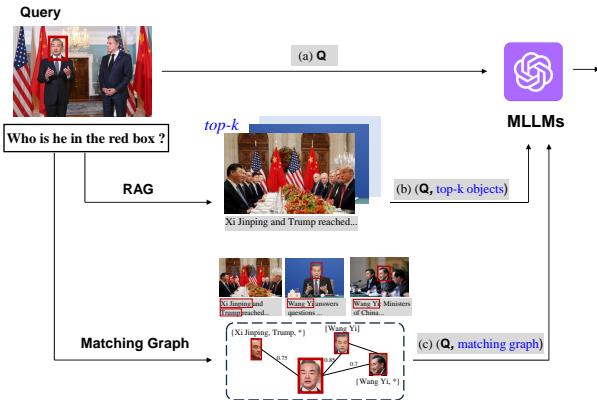
图 2 直观展示了三种不同的方法:
- 路径 (a) MLLMs: 直接将图像和问题输入模型。如前所述,由于缺乏知识或隐私拒绝,这通常会失败。
- 路径 (b) 粗粒度 RAG: 获取用户的图像,在数据库中搜索相似的新闻文章,并将前 5 篇文章 (图像 + 标题) 输入 MLLM。问题在哪里?噪音太多了。MLLM 会被多张完整的图像和长标题淹没,难以准确指出检索到的照片中哪个人与查询中的人相匹配。
- 路径 (c) 细粒度 RAG (MAR 方法) : 这是一个游戏规则改变者。
- 系统从查询中提取人脸 。
- 它在数据库中搜索相似的人脸 。
- 它提取与这些人脸相关的名字 。
- 它构建一个图 (节点 = 人脸/名字,边 = 相似度分数) 。
- 它将这个精确、干净的图输入给 MLLM。
构建匹配图
MAR 实际上是如何构建这个图的?这分为两个阶段: 离线索引和在线构建 。
1. 离线索引 (准备知识库)
在回答任何问题之前,MAR 会处理一组带标题的图像 (如新闻档案) 。
- 人脸识别: 它使用一个名为 DeepFace 的工具从图像中抠出每一张人脸。
- 名字识别: 它使用一个名为 spaCy 的工具从标题中提取名字。
- 编码: 它使用 CLIP (一种视觉-语言模型) 将这些人脸和名字转换为数学向量 (数字列表) 并存储在数据库中。
2. 在线图构建 (“侦探工作”)
当用户针对特定人脸 (种子节点) 问“这是谁?”时:
- 初始化: 系统从查询人脸开始。
- 扩展: 它查询向量数据库。“给我看与这张脸有 80% 相似度的脸。”它还会查找与这些人脸相关的名字。
- 迭代: 如果它找到了一个新的匹配人脸,它会查看那张脸是否有其他连接。它重复这个循环 (通常 2 次) 以构建一个小型的证据网络。
结果就是一个 匹配图 : 一个由人脸或名字作为节点,边代表系统对它们相关性信心的网络。
细粒度 RAG: 将图输入给 LLM
MLLM 无法直接“看”到图结构。它需要文本 (和图像) 。作者开发了一种方法来序列化图——将节点和边转换为模型可以阅读的文本序列。
他们使用以下方程定义序列化过程:
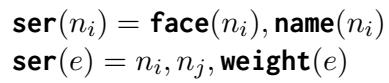
在这里,ser(n) 代表节点的序列化 (人脸图像及其可能的名字) ,ser(e) 代表边 (两个节点之间的连接及其相似度权重) 。
整个图 g 就是其所有节点和边的总和:
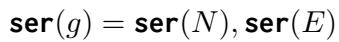
最后,系统将相关的人脸图像拼接成一张合成图像,并创建一个文本提示,内容是: “请告诉我 [问题]。如果你不确定,请阅读以下内容 [序列化图]。”
这提示 MLLM 充当推理者的角色。它不需要“认识”这个人;它只需要查看提示中提供的证据: “查询人脸与人脸 A 有 90% 的相似度,而人脸 A 被标记为‘王毅’。因此,查询人脸很可能是王毅。”
基准测试: NewsPersonQA
该领域的困难之一是缺乏好的数据集。大多数视觉问答数据集关注一般物体 (汽车、狗、飞盘) 。那些确实包含人物的数据集通常只关注一线名人。
为了有效测试 MAR,研究人员构建了一个名为 NewsPersonQA 的新基准。
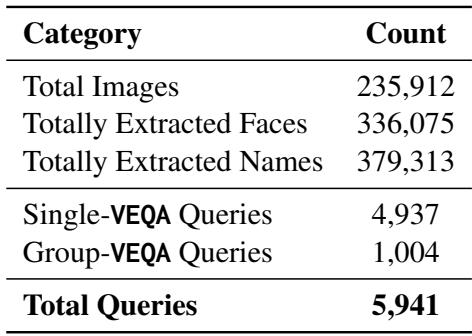
如 表 1 所示,这个数据集非常庞大,包含超过 235,000 张图像和近 6,000 个问答对。关键是,它区分了 Single-VEQA (询问单个人) 和 Group-VEQA (询问“有多少张图片包含唐纳德·特朗普?”) 。
该数据集最重要的特征是其身份的真实分布。在现实世界 (以及新闻) 中,少数人经常出现,但大多数人很少出现。这被称为“长尾”分布。
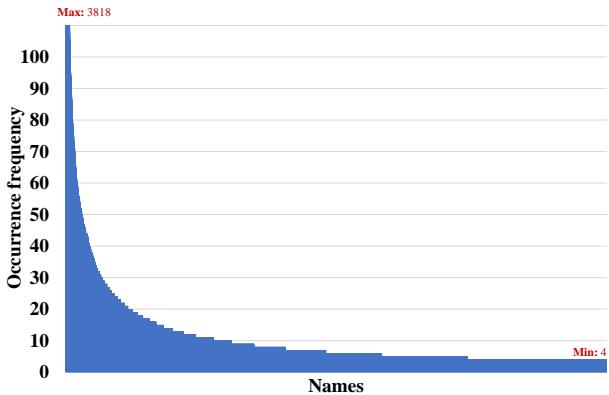
图 3 说明了这种分布。你可以看到左侧有一个巨大的峰值——这些人是特朗普和奥巴马之类的。然后曲线变平,形成一条非常长的尾巴。这些是“不常见的实体”——当地政治家、顾问或特定的新闻对象。这正是标准 MLLMs 失败的地方,也是 MAR 旨在发光发热的地方。
实验与结果
它真的有效吗?研究人员将 MAR 与标准 MLLMs (LLaVA 和 GPT-4V) 以及“粗粒度 RAG”方法进行了测试。
单一实体问题的表现
识别单个人的结果令人信服。
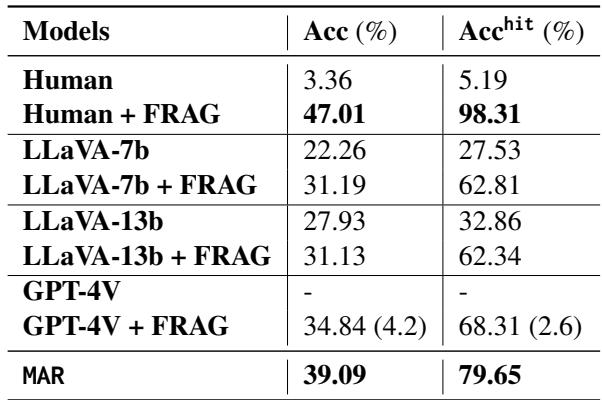
表 2 揭示了几个关键见解:
- 人类仍然是最棒的: “Human + FRAG” (给人类提供匹配图) 达到了近乎完美的准确率 (98.31%) 。这表明匹配图中包含了正确的答案;挑战在于让 AI 识别出来。
- MAR 优于原始 MLLMs: 使用 MAR 后,LLaVA-7b 的准确率从 22.26% 跃升至 39.09%。
- GPT-4V 与隐私: 看看 GPT-4V 这一行。没有 MAR 时,它拒绝回答 (用
-表示) 。有了匹配图 (FRAG) ,它达到了 34.84% 的准确率。
- 注意: * 这是一个迷人的结果。通过提供外部证据 (“这是一张标记为 X 人的相似人脸”) ,系统允许 GPT-4V 基于上下文*而不是面部识别记忆来回答,这似乎满足了它的安全策略。
常见与不常见实体
系统的真正考验在于数据的“长尾”部分——那些不出名的人。
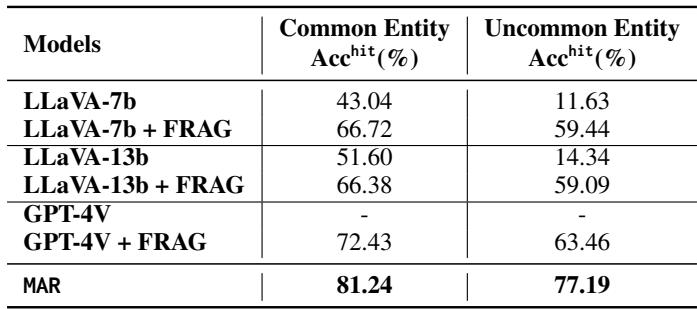
表 6 按知名度细分了准确率。
- 常见实体 (Common Entities) : 标准 LLaVA-7b 表现尚可 (43%) 。
- 不常见实体 (Uncommon Entities) : 标准 LLaVA-7b 表现崩盘 (11.63%) 。它根本不知道这些人是谁。
- MAR 效应: 当配备 MAR (此处标记为 FRAG 或 MAR) 时,针对不常见实体的准确率飙升至 77.19% (使用 MAR 算法) 。
这证明了假设: 检索增强推理拉平了竞争环境。 它让模型能够像识别名人一样有效地识别未知人物,只要数据库中至少有一个标记的参考即可。
结论与启示
这篇关于“MAR”的论文在使多模态 LLM 对现实世界信息检索更有用方面迈出了重要一步。通过将识别的重担从模型的内部权重转移到外部的结构化图上,我们获得了三大好处:
- 准确性: 我们可以有效地识别非著名人物。
- 可解释性: 模型可以指出证据 (“我认为这是 A,因为他们看起来像图像 B 中的人”) 。
- 合规性: 我们可以通过将答案建立在公共数据而非生物特征记忆之上,来潜在地规避隐私限制。
这种方法——细粒度 RAG——很可能是视觉-语言模型复杂推理的未来。与其将原始文档倾倒给 AI,我们正朝着将数据预处理为干净、逻辑结构 (如匹配图) 的方向发展,这使得 AI 能够做它最擅长的事情: 根据提供的事实进行推理。
对于学生和研究人员来说,这篇论文是一个很好的例子,展示了如何结合 符号 AI (图、结构化数据库) 与 神经 AI (LLMs、CLIP) 来解决两者单独都无法解决的问题。