](https://deep-paper.org/en/paper/file-3373/images/cover.png)
想象一下,你是一名机器学习工程师,负责为招聘平台部署一个大型语言模型 (LLM)。你运行了一个标准的偏差评估脚本,它返回了一个分数: 0.42 。
现在你该怎么做?
0.42 是好是坏?这是否意味着模型太糟糕了?这是否意味着模型仇视女性,或者只是稍微偏向西方名字?如果你修复了数据,分数降到了 0.38,模型是否就可以安全部署了?
如果你无法回答这些问题,那么你使用的指标就缺乏可行动性 (actionability) 。
在快速发展的自然语言处理 (NLP) 领域,我们看到了提出各种偏差度量新方法的论文呈爆炸式增长。然而,一篇题为 “Metrics for What, Metrics for Whom: Assessing Actionability of Bias Evaluation Metrics in NLP” 的最新论文指出,我们正在制造一些在根本上难以使用的工具。
作者 Pieter Delobelle, Giuseppe Attanasio, Debra Nozza, Su Lin Blodgett, 和 Zeerak Talat 对 146 篇研究论文进行了全面的审查。他们的结论是什么?该领域正遭受着清晰度缺失的困扰,这阻碍了我们将偏差测量转化为现实世界的干预措施。
在这次深度解读中,我们将探讨可行动性的概念、研究人员提出的评估框架,以及他们文献综述中发人深省的结果。
测量与行动之间的鸿沟
要理解为什么可行动性是必要的,我们需要先看看“公平 NLP (Fair NLP)”的现状。
多年来,研究人员一直使用社会科学中的测量建模 (measurement modeling) 等框架。这种方法要求我们区分构念 (construct) (我们要测量的理论概念,如“性别歧视”) 和操作化 (operationalization) (我们实际如何测量它,如“计算代词不匹配”) 。
虽然这种区分对于有效性 (测量我们认为正在测量的东西) 至关重要,但它忽略了一个实际组成部分: 效用 (utility) 。
在现实世界中,指标是决策的工具。2014 年,亚马逊曾试图构建一个 AI 系统来筛选简历。他们发现该系统会惩罚包含“women’s (女性的) ”一词的简历 (例如,“女性国际象棋俱乐部”) 。因为他们内部审计的结果清晰且具备可行动性,所以他们能够采取具体步骤: 他们尝试编辑程序,当失败后,最终放弃了该项目。
结果促成了一项决策。这就是可行动性的本质。
定义可行动性
作者将可行动性正式定义为:
度量结果促成知情行动的程度。
一个具备可行动性的结果能够传达谁受到了影响、伤害的规模或问题的来源。这使得利益相关者能够进行干预。干预措施可能包括:
- 开发人员: 更改训练数据或微调模型。
- 公司: 决定不发布模型或部署保障措施。
- 监管机构: 处以罚款或禁止特定的违规应用。
- 用户: 选择退出他们知道存在偏差的系统。
可行动性与可解释性 (interpretability) 或透明度 (transparency) 等概念相关,但又有区别。一个指标可能具有完美的可解释性 (你确切地知道数学原理) ,但不具备可行动性 (那个数字并没有告诉你该模型是否可以安全使用) 。
必要条件: 什么让指标具备可行动性?
这就引出了这篇论文的核心贡献: 一个用于评估偏差指标是否具备可行动性的框架。作者确定了五个关键的“必要条件 (desiderata)”——即一篇研究论文应该提供的要求——以使其提出的指标真正有用。
如果你是开发新指标的学生或研究员,这是你必须回答的五个问题。
1. 动机 (Motivation)
要求: 清楚地陈述该度量方法所解决的需求。 为何重要: 这个指标是用来检测招聘中的直接歧视吗?还是为了检查模型如何处理特定方言?或者它是针对以前的指标未涵盖的新语言? 如果用户不了解具体的动机,他们就无法确定该指标是否适合他们的具体问题。一个为“情感分析”设计的指标,即使都测量“性别偏差”,对于“文本生成”来说也可能是毫无用处的。
2. 潜在的偏差构念 (Underlying Bias Construct)
要求: 明确定义这种语境下的“偏差 (bias)”意味着什么。 为何重要: “偏差”是一个模糊且过载的术语。它可以指统计偏斜、社会刻板印象、分配性伤害 (拒绝资源) 或表现性伤害 (贬低某个群体) 。 可行动性需要理论上的理解。如果论文没有定义构念,那么数字就只是噪音。例如,如果一个指标声称测量“性别偏差”,但只检查二元代词 (他/她) ,那么它在操作上就未能捕捉到非二元性别身份。如果没有清晰的定义,开发人员可能会认为他们的模型对所有人都是“公平”的,而实际上它只对特定的子集“公平”。
3. 区间与理想结果 (Interval and Ideal Result)
要求: 定义分数的可能范围,尤其是“理想”分数是什么样的。 为何重要: 这通常是从业者最大的痛点。
- 定义域: 分数是实数吗?百分比?
- 区间: 它是有界的 (如 0 到 1 之间) 还是无界的 (如对数似然) ?
- 理想值: 目标是什么?0 是完美吗?50 是完美吗?
如果一个指标是无界的 (例如,它可以从负无穷大到正无穷大) ,那么它很难被付诸行动。如果你的分数从 150 提高到 120,这显著吗?还是说任何高于 10 的分数都是不可接受的?如果没有“理想结果” (一个规范性标准) ,决策者就无法设定部署的门槛。
4. 预期用途 (Intended Use)
要求: 指定指标适用的条件。 为何重要: 没有哪个指标是万能药。有些是专门为掩码语言模型 (如 BERT) 设计的,在生成式模型 (如 GPT) 上无法工作。有些需要特定的数据集格式 (如刻板印象对) 。 通过明确说明预期用途——包括必要的数据、模型类型和社会背景——研究人员可以防止误用。在预期范围之外使用指标是产生错误自信的根源。
5. 可靠性 (Reliability)
要求: 提供证据证明该指标是一致且稳健的。 为何重要: 如果你运行两次测试,会得到相同的结果吗?如果你稍微改变种子词,偏差分数会反转吗? 可靠性是可行动性的先决条件。如果一个指标的误差幅度很大,你无法基于它做出商业或政策决策。论文应报告误差幅度、统计显著性检验和稳健性检查。
审计: 该领域的表现如何
为了观察 NLP 社区是否达到了这些标准,作者进行了系统性的文献综述。他们不仅仅是挑选著名的论文;他们遵循了严格的筛选过程。
正如下面的 PRISMA 流程图所示,他们从 ACL Anthology (NLP 研究的主要资料库) 中的近 1200 篇论文开始。在根据相关性进行过滤后——具体寻找引入新偏差指标或数据集的论文——他们将其缩小到最终的 146 篇论文 。
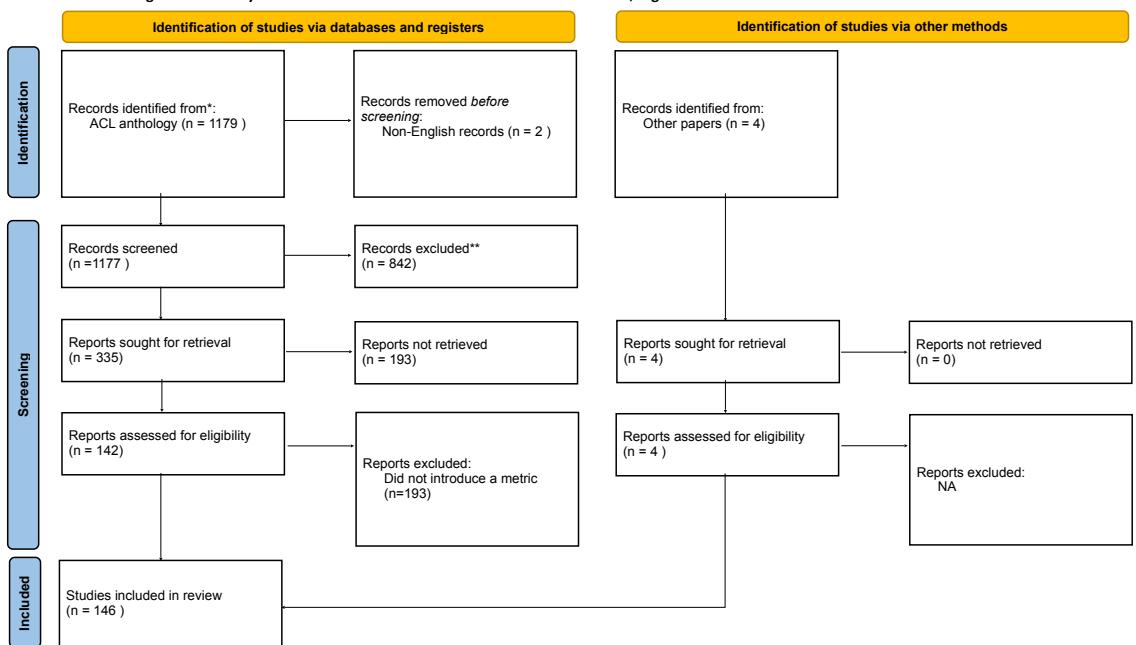
随后,研究人员阅读了这 146 篇论文中的每一篇,并根据五个可行动性必要条件对它们进行了注释。结果揭示了整个领域中存在的重大“对可行动性的威胁”。
威胁 1: 模糊的动机
虽然 80% 的论文提供了某种动机,但许多动机都极其模糊。一种常见的模式是循环逻辑: “我们引入一个新的性别偏差指标,因为现有的指标无法测量这种特定类型的性别偏差”,却不解释为什么这种特定类型在现实世界中很重要。
有些论文引用了未详细说明的“威胁”作为动机。例如,一篇论文仅引用“LangChain” (一个用于构建 LLM 应用的库) 作为一种危险来作为其工作的动机,却没有解释具体的风险是什么。如果动机不明确,从业者就无法知道该指标是否解决了他们的实际问题。
威胁 2: 缺失的构念
也许最令人震惊的发现是,在 25% 的论文中,根本无法确定作者打算测量什么样的理论偏差构念。
这忽略了测量的一个基本规则: 你无法测量你没有定义的东西。许多论文跳过了定义,直接进入操作化阶段,通常只是简单地复制以前的方法 (如词嵌入关联测试,WEAT) ,而不质疑它是否适合当前的语境。
当构念缺失时,“偏差”就变成了数学抽象,而不是社会现实。这使得干预变得不可能——如果指标只给你一个向量距离,你就无法修复社会伤害。
威胁 3: “理想”分数的谜团
大多数论文 (82%) 报告了其指标的范围 (例如,“分数范围从 0 到 1”) 。然而,如何解释这些分数通常留给了读者自己去参悟。
只有 32% 的论文在涉及理想结果时,实际讨论了该结果意味着什么,或者如何解释与理想值的偏差。
作者强调了 “StereoSet” 论文 (Nadeem et al., 2021) 中的一个正面例子,该论文明确定义了一个 IdealLM (理想语言模型) :
“我们将这个假设模型定义为一个总是选择正确关联的模型……它还在所有目标术语中选择了[相同]数量的刻板印象和反刻板印象关联……因此,结果 lms 和 ss 分数分别为 100 和 50。”
这种程度的清晰度是罕见的。没有它,获得“65”分的用户就没有参考点。65 离 50 够近吗?还是严重偏差的证据?
威胁 4: 忽视可靠性
可靠性是信任的基础。如果温度计每次接触都会给出不同的读数,你就不会用它来检查发烧。然而,审查发现,可靠性在偏差指标的开发中很大程度上被忽视了。
下表按论文的动机分类,对比了它们是否讨论了可靠性。

正如我们在表中所见, 只有 28 篇论文 (约 19%) 明确讨论了其新方法的可靠性 (由 \(R_Y\) 列表示) 。
更引人注目的是表格的第一行。有 19 篇论文是专门由于现有度量方法缺乏可靠性而受到启发去做的。然而,在这 19 篇论文中, 有 11 篇甚至没有评估它们自己提出的方案的可靠性 。
这表明了一种令人不安的趋势: 研究人员承认该领域存在可靠性问题,引入了一个“更好”的指标,却未能证明他们的新指标实际上更可靠。
讨论: 如何修复偏差指标
这篇论文的发现敲响了警钟。我们正在建立一个庞大的“公平性工具”库,但其中许多都是钝器,无助于我们修复底层系统。
作者提出了一些建议,以推动该领域走向具备可行动性的科学。
1. 将指标建立在影响与危害之上
对于计算机科学家来说,数字是舒适的;社会影响是混乱的。然而,为了使指标具备可行动性,数字必须与伤害相关联。
- 不要只说: “分数是 0.8。”
- 要说: “0.8 的分数对应于女性候选人的简历排在前 10 名的概率降低了 20%。”
当结果建立在预期行为之上时,开发人员可以在模型准确性和公平性之间做出明智的权衡。
2. 明确界定预期用途的范围
研究人员需要停止暗示他们的指标是通用的。如果一个指标是为使用 BERT 的英语新闻文章设计的,请说明这一点。如果将其应用于使用 GPT-4 的法语医疗记录,它可能会完全失败。明确的范围界定有助于用户为工作选择正确的工具。
3. 论证偏差定义的合理性
我们需要摆脱将“偏差”作为一个包罗万象的术语。论文应该阐明它们正在测量的具体构念。它们是在测量“刻板印象关联”?“有毒的补全”?还是“排他性语言”? 将指标与特定的社会构念 (例如,使用社会学或心理学的文献) 联系起来,可以增强工作的有效性,并阐明需要采取什么具体的干预措施。
4. 可靠性没得商量 (必须具备)
最后,社区必须要求进行可靠性评估。一个新的指标应该带有误差条。它应该针对不同的种子词或输入句子的轻微改写进行稳定性测试。如果一个指标不稳定,它不仅仅是无用的——它是危险的,因为它可能会给模型部署者带来错误的安全感 (或错误的警报) 。
结论
论文 “Metrics for What, Metrics for Whom” 为 NLP 社区引入了一套关键的词汇体系。通过将重点从有效性 (数学是正确的吗?) 转移到可行动性 (我们能使用它吗?) ,它挑战研究人员去思考他们工作的下游消费者。
对于学生和从业者来说,教训很清楚: 对分数保持怀疑。当你遇到偏差指标时,问一些尖锐的问题。理想分数是多少?构念是什么?这可靠吗?
如果指标无法回答这些问题,它就无法帮助你建立一个更公平的系统。而构建更公平的系统,归根结底,才是唯一重要的指标。