](https://deep-paper.org/en/paper/file-3426/images/cover.png)
引言
当我们回想历史时,我们通常会将其可视化。我们会联想到 19 世纪后期的泛黄照片、不断扩张的城市的工业烟雾,或者是维多利亚时代的时尚。但是,你是否曾停下来想过,过去听起来是什么样的?
在录音技术出现之前,听觉世界是转瞬即逝的。我们无法聆听 1880 年哥本哈根街头的声音。然而,我们有“听觉见证者” (earwitnesses) ——那些生活在那个时代并通过文学记录下感官环境的作家。斯堪的纳维亚“现代突破” (1870–1899) 时期的这部小说充满了马车的喧嚣、新式蒸汽机的嘶嘶声以及城市人群的低语。
对于历史学家和文学学者来说,分析这些声音为理解社会在快速工业化过程中的变迁提供了一个独特的窗口。但存在一个后勤问题: 在数百部小说中寻找每一处关于声音的提及需要花费一个人毕生的时间。
这就引出了研究论文《噪音、小说、数字》 (Noise, Novels, Numbers) 。在这项研究中,来自哥本哈根大学和加州大学伯克利分校的研究团队开发了一个计算框架,用于检测和分类文学作品中的“噪音”。通过结合主题模型 (Topic Modeling) 与微调后的大型语言模型 (LLM) ,他们分析了 800 多部小说,以此重建 19 世纪的声景。
在这篇文章中,我们将拆解他们的方法论,探讨他们如何教计算机识别“噪音”,并看看数据告诉了我们关于维多利亚时代音量的哪些信息。
背景: “听诊时代”
为了理解这项研究的重要性,我们需要了解那个时代的背景。斯堪的纳维亚的 19 世纪后期是一个发生激进变革的时期。哥本哈根的人口呈爆炸式增长,从有轨电车到工厂的新技术入侵了听觉空间。
学者们常将这一时期称为“听诊时代” (auscultative age) 。这个术语借用于医学 (用听诊器听诊身体) ,用来描述一个人们对声波环境变得高度敏感的时代。噪音不仅仅是背景;它是现代性、进步的标志,有时也是社会衰退的标志。
定义噪音的挑战
在研究人员能够训练模型找到噪音之前,他们必须先定义它。这比听起来要难。在声音研究中,噪音通常被主观地定义为——“不合时宜的声音”或不需要的声音。然而,教计算机理解“不需要”是很困难的,因为它在很大程度上依赖于特定角色的情绪或语境。
取而代之的是,作者采用了一个更具操作性的定义: 噪音是“打破沉默的事物” (silence-breaking) 。
这个宽泛的定义包括:
- 异常声音: 尖叫、爆炸、撞击。
- 中性声音事件: 工厂汽笛、脚步声。
- 低音量声音: 低语或咕哝,只要它们被记录为打破了沉默。
语料库
为了大规模地“阅读”声景,研究人员利用了 MeMo 语料库 , 这是一个海量的丹麦和挪威文学数字集合。

如表 1 所示,语料库非常庞大。它包含 859 部小说,由超过 6400 万个单词组成。文本被分解为近 200 万个片段 (文本块) 。这种分段对于机器学习至关重要,因为它允许模型分析可管理的上下文片段,而不是一次吞下整部小说。
核心方法: 声音处理管线
这就篇论文的核心在于其方法论。作者并没有简单地让 ChatGPT “找出噪音”。他们构建了一个严格的、多步骤的管线,结合了无监督学习 (主题建模) 和有监督学习 (微调的 BERT 模型) 。
工作流程如下图所示。我们将分解这个过程的每个组成部分。
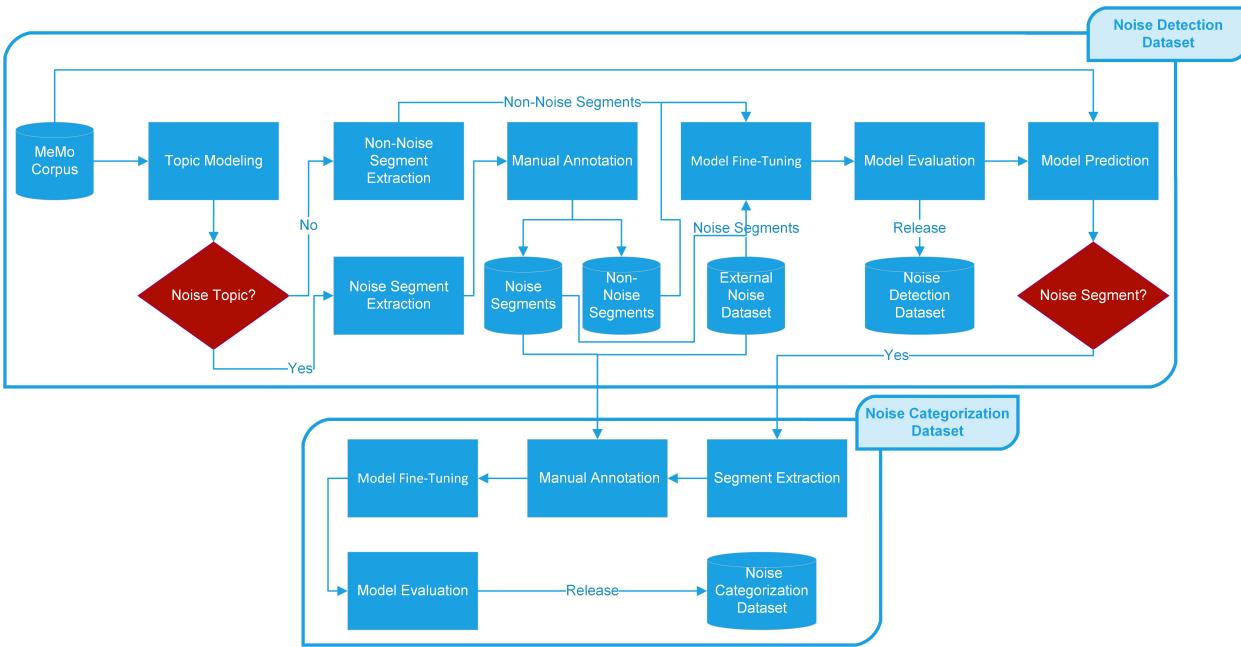
第一步: 用于信号提取的主题建模
在 6400 万字的资料库中,第一个挑战是大海捞针。小说中的大多数段落描述的是视觉、内心想法或并未明确“嘈杂”的对话。
为了过滤数据,研究人员使用了 BERTopic 。 这是一种基于语义相似度对文档 (或本例中的文本片段) 进行聚类的技术。通过分析整个语料库,模型将片段分组为不同的主题。然后,研究人员手动检查这些主题,以找到与声音相关的主题。
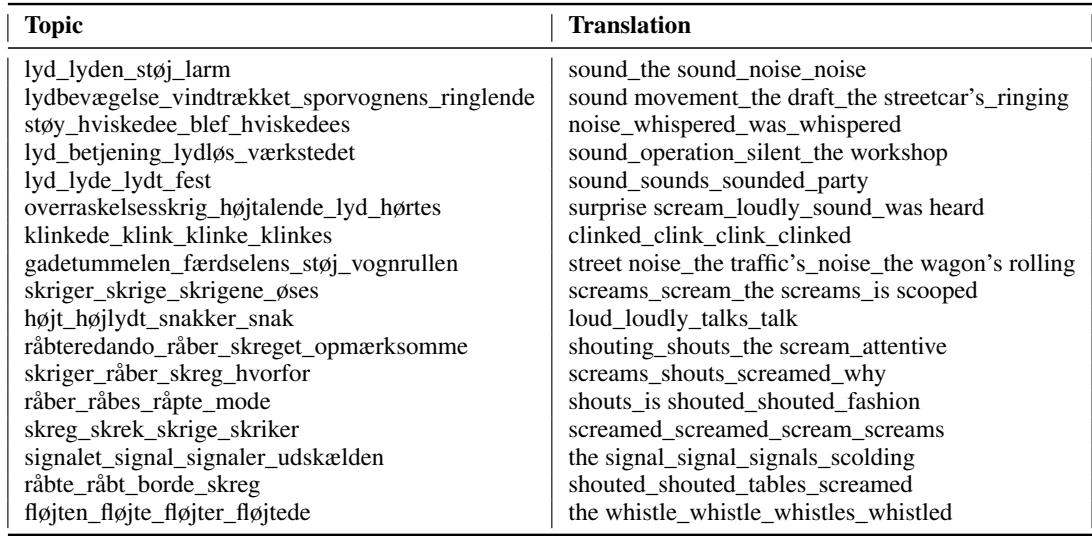
表 2 展示了这种方法的有效性。模型识别出了明显指示听觉事件的单词群。你可以看到围绕“尖叫/呼喊” (主题 11、12、13) 、像汽笛和有轨电车这样的“机械声音” (主题 2、17) 以及一般性的“噪音/喧闹” (主题 1、8) 的主题。
在数百万个可用片段中,这一过滤过程将范围缩小到了约 5,700 个可能包含噪音的高概率片段。
第二步: 人工标注与定义
算法的优劣取决于训练它们的数据。为了给 AI 创建“基准真相” (ground truth) ,人类专家 (历史学家和文学学者) 手动标注了数据的一个子集。
他们必须做出二元决策: 这个片段是噪音吗? (是/否) 。
他们遵循严格的准则:
- 隐喻不是噪音: “她感觉到一股嗡嗡作响的电流”是一种感觉,而不是声音。这被标记为 0 (非噪音) 。
- 否定不是噪音: “没有任何噪音”虽然提到了“噪音”这个词,但描述的是寂静。这被标记为 0。
- 音乐是噪音: 遵循“打破沉默”的规则,音乐算作声音事件。
这一过程创建了一个训练集,模型可以通过它学习用作隐喻的“声音”一词与实际物理声音描述之间的区别。
第三步: 分类
检测噪音是第一步。理解是什么发出了噪音是第二步。研究人员回到数据中对噪音源进行分类。这对于历史分析至关重要——我们想知道 19 世纪变得更加嘈杂是因为人还是因为机器。
他们建立了四个类别:
- 非人造 (Non-human made) : 自然 (风、雷) 和机器 (蒸汽机、有轨电车) 。请注意,即使人类操作机器,声音本身也是机械的。
- 人造 (Human-made) : 声音、脚步声、尖叫、掌声。
- 音乐 (Music) : 乐器和歌唱。这被单独列出,因为它与传统意义上的“噪音”不同,但绝对是一个声音事件。
- 未定义 (Undefined) : 来源不明确的模糊声音 (例如,“一般的嗡嗡声”) 。

表 3 显示了训练数据中这些类别的分布。有趣的是,非人造噪音 (40%) 和人造噪音 (33%) 相当平衡,这为稍后对完整语料库的有趣分析奠定了基础。
第四步: 微调语言模型
有了干净、已标注的数据集,研究人员进入了建模阶段。他们没有从头构建模型,而是使用了迁移学习 。
他们选择了现有的预训练模型——具体是 DanskBERT 和 MeMo-BERT (一个已经针对历史丹麦语进行调整的模型) ——并对它们进行了“微调”。微调涉及采用一个已经理解丹麦语的模型,并在识别噪音片段这一特定任务上对其进行进一步训练。
这类似于让一个已经精通丹麦语的学生参加“19 世纪声音研究”的速成班。
实验与结果
研究人员进行了两项主要实验: 噪音检测 (二分类: 它是噪音吗?) 和噪音分类 (多分类: 什么类型的噪音?) 。
模型性能
AI 的表现如何?这里使用的主要指标是 F1 分数 (F1-Score) , 它平衡了精确率 (Precision,选出的项目中有多少是相关的) 和召回率 (Recall,有多少相关的项目被选出) 。1.0 的 F1 分数是完美的。
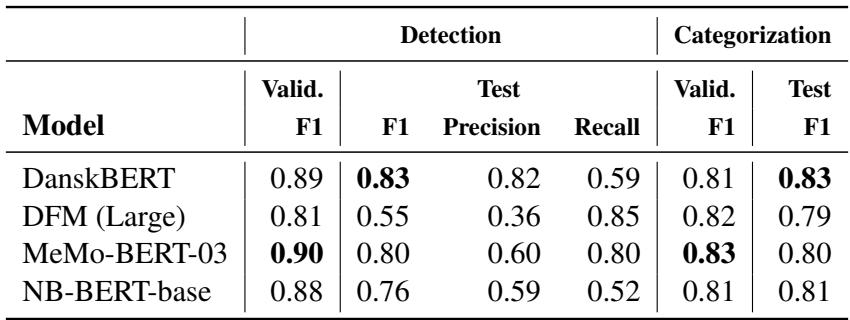
表 4 揭示了结果。
- DanskBERT 是表现最突出的模型。在噪音检测方面,它在测试集上取得了 0.83 的 F1 分数。对于语言可能微妙且富有诗意的文学任务来说,这是一个非常强劲的结果。
- 对于噪音分类 , DanskBERT 同样取得了 0.83 的 F1 分数。
有趣的是,专门在历史文本上训练的 MeMo-BERT 在测试集上的表现 (0.80) 略逊于通用的现代 DanskBERT。作者认为,由于 DanskBERT 是在海量的现代语料库上训练的,它可能更擅长检测“现代性信号”,或者仅仅是因为它具有更强大的通用语言结构理解能力,从而有助于更好地泛化到未见过的数据。
19 世纪的声景
一旦最佳模型 (DanskBERT) 经过训练和验证,研究人员就将其应用于整个 MeMo 语料库——全部 190 万个片段。这使得他们能够绘制随时间变化的噪音频率图,将文学分析转化为数据科学。
结果 1: 过去变得更嘈杂了
第一个主要发现证实了历史假设: 19 世纪后期正变得越来越嘈杂。
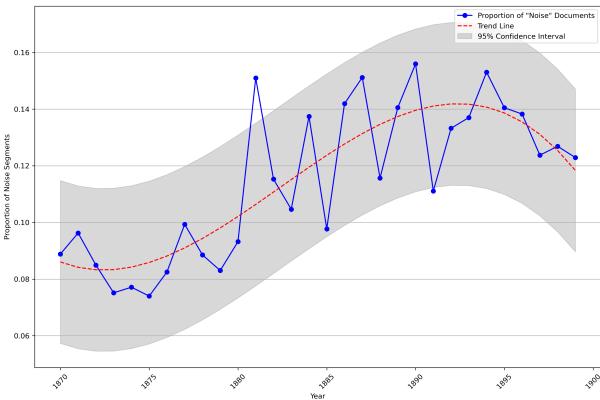
图 2 展示了 1870 年至 1900 年间包含噪音的文本片段比例。
- 趋势: 橙色虚线趋势线显示出明显的上升轨迹。从 19 世纪 70 年代到 90 年代,噪音相关片段的相对增长超过了 50% 。
- 解读: 这不仅意味着世界变得更嘈杂;这意味着作者们更多地描写噪音。角色的感官体验越来越多地被听觉干扰所定义。
- 平台期: 你会注意到在世纪之交 (1900 年) 左右有一个轻微的下降或平台期。作者推测,噪音可能变得如此普遍,以至于作者不再将其视为值得注意的事物——它变成了背景。
结果 2: 谁制造了噪音?
第二项分析着眼于噪音的类型。关于工业革命的一个普遍假设是,机器噪音会激增,而其他声音则保持不变。
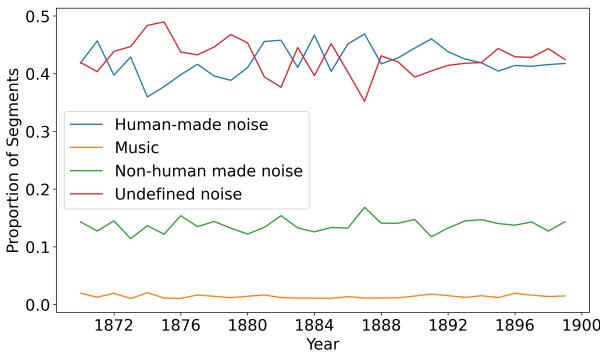
图 3 描绘了一幅更细致的画面。
- 稳定性: 令人惊讶的是,噪音类型的分布保持相对稳定。
- 人造噪音 (蓝线) : 这仍然是主导类别,徘徊在 40-45% 左右。尽管引入了有轨电车和工厂,文学人物最沉迷的仍然是其他人的声音——喊叫、谈话和移动。
- 非人造噪音 (绿线) : 这部分稳定在 15% 左右。
- 未定义噪音 (红线) : 很大一部分噪音被抽象地描述。
为什么这很重要? 人造噪音的持续存在反驳了“现代突破”仅仅是关于机器淹没人类的观点。这与伦敦和巴黎等城市的历史记录相吻合,那里的“反噪音”运动往往集中在街头音乐家和叫卖的小贩身上,而不仅仅是工业机械。文学反映了一个人口密度与新技术一样具有声学侵入性的社会。
结论与启示
《噪音、小说、数字》这篇论文展示了将传统人文探究与现代计算方法相结合的力量。通过训练语言模型去“聆听”文本,研究人员能够量化一种在一个多世纪前就已消失的感官体验。
主要收获:
- 方法论行之有效: 可以对标准 BERT 模型进行微调,以高准确率 (83% F1 分数) 识别像“打破沉默的事件”这样抽象的文学概念。
- 历史是嘈杂的: 19 世纪后期斯堪的纳维亚文学中的噪音频率增加了 50%,反映了该时期的城市化进程。
- 人类是嘈杂的: 尽管工业化了,但人类产生的声音仍然是小说中最常被引用的噪音形式,挑战了机器完全接管声景的叙事。
这个框架为未来迷人的研究打开了大门。我们能否将这些声音映射到历史上的哥本哈根特定街区,看看哪里是“嘈杂”区,哪里是“安静”区?我们能否将其应用于英国或法国文学,看看伦敦或巴黎的“听诊时代”听起来是否有所不同?
通过将小说转化为数字,我们并没有失去艺术;我们获得了一种体验它的新感官。我们终于可以听到过去的背景杂音了。