](https://deep-paper.org/en/paper/file-3577/images/cover.png)
引言
想象一下,你正在构建一个旨在扮演特定角色的 AI 应用程序——也许是一个海盗、一位正式的管家,或者是像《原神》 (Genshin Impact) 里的游戏角色。你找来了一个庞大的大语言模型 (LLM) ,但面临着一个问题: 为了让模型说话的语气完全像你的角色,通常需要成千上万个例句来进行微调。
但是,如果你只有 50 个例子呢?甚至只有 10 个?
在自然语言处理 (NLP) 领域,这被称为低资源文本风格迁移 (Low-Resource Text Style Transfer, TST) 问题。传统的微调在这里通常会失败,导致过拟合,或者模型完全忘记了如何说人话。即使是像 GPT-4 这样强大的模型的少样本提示 (Few-shot prompting) ,在生产环境中也可能表现不稳定或成本过高。
这就引出了一篇引人入胜的论文,题为 《Reusing Transferable Weight Increments for Low-resource Style Generation》 (复用可迁移权重增量以实现低资源风格生成) 。 研究人员介绍了一个名为 TWIST 的框架。其核心思想直观但在技术上很复杂: 与其从头开始学习一种新风格,为什么不“借用”模型已经学过的其他风格的知识呢?
在这篇文章中,我们将剖析 TWIST,了解它如何构建风格知识“池”,并利用巧妙的数学方法将这些知识迁移到新的、数据稀缺的任务中。
背景: 风格迁移的挑战
文本风格迁移旨在将文本重写为特定风格 (例如,从非正式到正式,或从中性到莎士比亚风格) ,同时保留原始含义。
标准方法是微调 (Fine-Tuning) 。 你采用一个预训练模型 (如 T5 或 LLaMA) ,并在特定数据集上更新其参数 (\(\theta\)) ,以最大化给定输入 (\(x\)) 时目标风格输出 (\(y\)) 的概率。
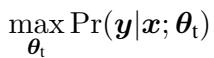
然而,更新所有模型参数不仅计算量大,而且需要大量数据。这导致了参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT) 的兴起,特别是 LoRA (低秩自适应) 。
LoRA 简介
要理解 TWIST,你必须理解 LoRA。LoRA 不直接更改模型的巨大权重矩阵,而是将小的、可训练的秩分解矩阵注入到模型中。
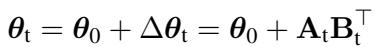
在这里,\(\theta_0\) 是冻结的预训练权重,\(\Delta \theta_t\) 是“权重增量”——即学习新任务所需的特定变化。LoRA 将此变化近似为两个较小矩阵 \(\mathbf{A}\) 和 \(\mathbf{B}\) 的乘积。
洞察: 研究人员意识到,这些“权重增量” (\(\Delta \theta\)) 包含集中的风格知识。如果我们能从各种源任务 (如情感迁移或形式迁移) 中对这些增量进行编目,我们就有可能通过组合和匹配它们来启动全新风格的学习。
TWIST 框架
TWIST 代表 reusing Transferable Weight Increments for Style Text generation (复用可迁移权重增量以生成风格文本) 。 它主要分为两个阶段:
- 准备阶段: 构建风格知识库 (池) 。
- 优化阶段: 检索并调整该知识以用于新的低资源目标。
让我们看看高层架构:
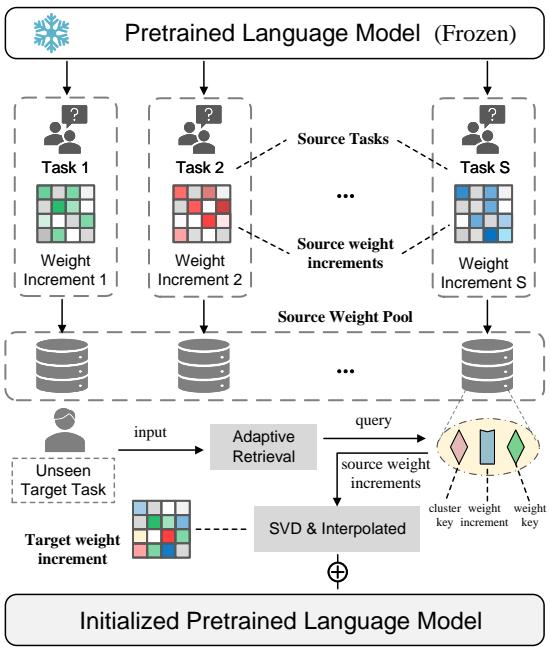
如图 1 所示,系统从一个冻结的预训练语言模型开始。它从各种“源任务”中学习,创建一个“源权重池”。当一个“未见过的目标任务”到来时,系统使用自适应检索机制从池中提取最相关的权重,合并它们,并为新任务初始化模型。
让我们分解每个步骤中的技术创新。
1. 构建权重池
首先,研究人员在几个高资源源任务 (拥有大量数据的任务) 上训练模型。对于每个任务,他们学习一个特定的权重增量 \(\Delta \theta_s\)。
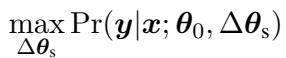
训练完成后,这些增量不仅仅是被扔进一个文件夹。它们被组织成一个多键记忆网络 (Multi-Key Memory Network) 。
在标准的键值存储中,你使用键来查找值。在 TWIST 中,“值”是权重增量 (\(\Delta \theta_s\)) 。但是我们如何定义“键”呢?论文引入了存储在结构 \(\mathbf{P}\) 中的双键系统:
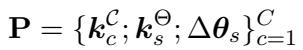
存储 \(\mathbf{P}\) 包含:
- 权重键 (\(k_s^\Theta\)) : 代表源风格特定语义特征的向量。
- 聚类键 (\(k_c^\mathcal{C}\)) : 代表一组相似风格的向量 (使用谱聚类进行聚类) 。
- 值 (\(\Delta \theta_s\)) : 实际的 LoRA 参数。
这种结构允许模型既能在高层次上进行搜索 (“我需要一些正式的东西”) ,也能在细粒度上进行搜索 (“我需要一些特别像这个句子的东西”) 。
2. 自适应知识检索
现在,假设我们有一个新的目标句子 \(x\),想要将其转换为一种新风格 (例如“《原神》角色”) 。我们目前还没有针对此的训练权重。
TWIST 使用冻结的 BERT 模型从输入文本 \(x\) 中提取特征。这些特征充当查询 (Query) 。 系统将此查询与记忆池中的键进行比较,以计算检索分数 (Retrieval Score, \(\mathcal{R}_s\)) 。
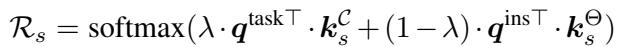
上面的公式至关重要。分数 \(\mathcal{R}_s\) 决定了特定源风格应该有多大的“影响力”。它是一个加权组合 (由 \(\lambda\) 控制) ,包括:
- 任务级相似度: 宽泛的任务有多相似?
- 实例级相似度: 这个特定的输入句子与源风格领域的相似度如何?
3. 使用 SVD 复用权重
这可能是论文中最具创新性的部分。一旦我们有了检索分数,理论上我们可以直接将源池中的 LoRA 矩阵相加。
问题: 简单地将参数矩阵相加通常会导致“参数干扰”。来自不同任务的权重可能会发生冲突,产生噪音,从而损害性能而不是帮助性能。
解决方案: 研究人员使用了奇异值分解 (SVD) 。 他们分解检索到的 LoRA 矩阵,只保留前 \(q\) 个奇异值和向量。
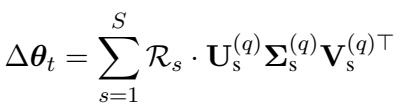
通过仅使用最重要的奇异向量 (矩阵 \(\mathbf{U}\)、\(\boldsymbol{\Sigma}\) 和 \(\mathbf{V}\)) 重构权重增量 \(\Delta \theta_t\),他们实质上是对权重进行了去噪。它的作用就像一个过滤器,保留强烈的风格信号,同时丢弃导致干扰的噪音。
最后,这个构建好的 \(\Delta \theta_t\) 作为一个热启动初始化 。 然后,模型在可用的少量目标数据上进行微调,最小化标准损失函数:
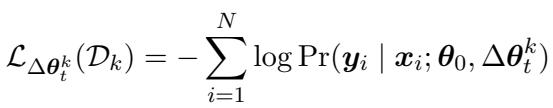
实验与结果
为了测试 TWIST,作者使用了多样化的数据集,包括 Shakespeare (写作风格) 、Genshin (角色扮演 6 个不同角色) 、YELP (情感) 和 GYAFC (正式度) 。
他们将 TWIST 与强大的基线进行了比较:
- 小规模: 使用标准微调和其他迁移方法的 T5-Large。
- 大规模: 使用 QLoRA 和 GPT-4 少样本提示 (Few-Shot prompting) 的 LLaMA-2-7B。
LLaMA-2 上的表现
大语言模型上的结果令人印象深刻。下面是全量数据集的比较表。
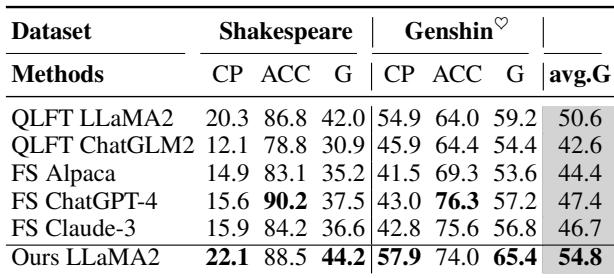
请看 G-score (准确性和内容保留的几何平均值) 。TWIST (Ours LLaMA2) 达到了 54.8 的 G-score,优于标准的 QLoRA 微调 (50.6) ,甚至击败了 Few-Shot ChatGPT-4 (47.4) 和 Claude-3 (46.7) 。这表明通过 TWIST 进行监督初始化比提示工程在风格一致性方面更稳定。
低资源情况剖析
TWIST 的真正威力显现于数据稀缺时。研究人员通过仅使用 1%、2%、5% 和 10% 的训练数据来模拟低资源场景。
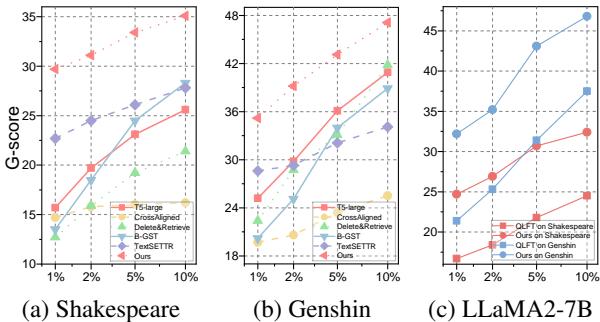
在 图 2(a) (莎士比亚) 中,请看红线 (Ours) 。在 1% 的数据使用量下,TWIST 保持了较高的 G-score,而其他方法 (如 CrossAligned 或 TextSETTR) 则完全崩溃。 在 图 2(c) 中,你可以看到 LLaMA-2 的轨迹。即使数据量极少,权重池提供的“热启动”也允许模型立即收敛到不错的性能。
为什么 SVD 很重要?
作者声称使用 SVD 合并权重比标准合并更好。他们通过消融实验证明了这一点。
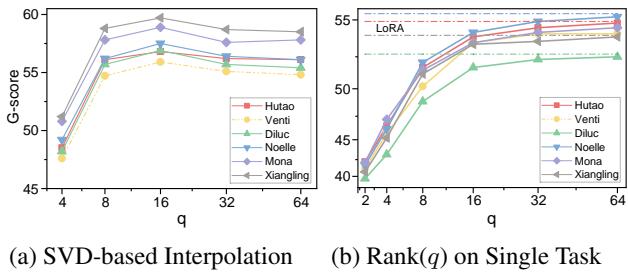
图 4 (左) 显示了基于秩 \(q\) 的性能。如果 \(q\) 太小 (x 轴左侧) ,我们会丢失太多信息。如果 \(q\) 太大 (右侧) ,我们会引入噪音/干扰。最佳点似乎在 \(q=16\) 左右。这验证了“稀疏”合并比密集合并对迁移学习更有效的假设。
风格空间可视化
为了确认模型确实在学习不同的风格,研究人员对生成文本的风格特征进行了可视化。

在这些 UMAP 图中, 红点是源文本 (原始风格) , 金点是目标参考。 蓝点 (TWIST 输出) 与金色簇有显著重叠。这种视觉确认表明 TWIST 成功地将文本分布转移到了目标风格空间。
与其他方法的比较
为了完整性,以下是 TWIST 在像 T5 这样较小模型上与其他方法的比较。
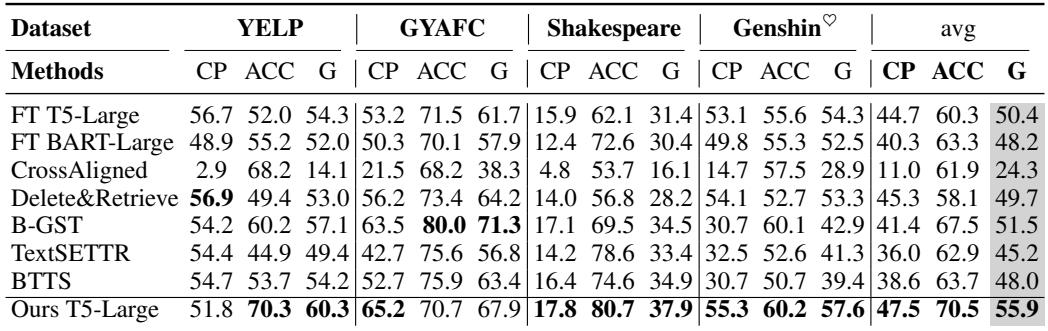
即使在 T5-Large 上,TWIST 在大多数指标上也优于以前的 SOTA 方法,如 “Delete&Retrieve” 和 “B-GST”。
结论
TWIST 论文为 AI 中的可重用性提出了令人信服的论据。与其将每个新的风格迁移任务视为一张白纸,我们不如将“风格”视为一种模块化、可迁移的资产。
关键要点:
- 不要从零开始: 使用来自其他任务的相关权重初始化模型可显著降低数据需求。
- 组织你的知识: 具有任务级和实例级检索功能的结构化权重池允许精确的知识迁移。
- 巧妙合并: 你不能简单地将神经网络权重相加。像 SVD 这样的技术对于提取有用信号并滤除噪音至关重要。
对于学生和从业者来说,TWIST 证明了你并不总是需要海量数据集或最大的专有模型才能达到最先进的结果。有时候,你只需要一种更聪明的方法来使用你已有的参数。