](https://deep-paper.org/en/paper/file-3697/images/cover.png)
引言
我们生活在一个数据洪流的时代。虽然我们经常将“大数据”想象为电子表格或 SQL 数据库中整齐的行和列,但现实却要混乱得多。世界上大量的信息——尤其是在法律、金融和社会科学等领域——被锁定在非结构化文本中。想想法院判决书、公司公告、历史档案和政策文件。这些文件包含关键的统计信息,但将这些信息提取到结构化表格中 (一项被称为 文本到表格/Text-to-Table 的任务) 是出了名的困难。
多年来,自然语言处理 (NLP) 社区一直致力于解决这个问题,但学术基准与现实世界的需求之间存在着巨大的脱节。现有的模型可能擅长将简短的维基百科传记转换为信息框,但在面对一份详述涉及多个借款人、担保人和利息计算的复杂贷款纠纷的 20 页法律判决书时,它们就会崩溃。
它们为什么会失败?因为传统方法通常假设表格结构简单且预先已知。它们将任务视为简单的序列生成问题。但在现实世界中,结构是复杂的,文本是冗长的,关系是错综复杂的。
在这篇文章中,我们将深入探讨一篇提出范式转变的研究论文。我们将探索 TKGT (Text-KG-Table) , 这是一个重新定义文本到表格任务的框架。该方法引入了一个源自中国法律判决书的全新、高难度数据集,并提出了一种新颖的两阶段管道,利用 知识图谱 (Knowledge Graphs, KGs) 作为原始文本和结构化表格之间的桥梁。
阅读完本文,你将了解为什么传统的文本到表格方法在处理复杂文档时举步维艰,知识图谱如何指导大型语言模型 (LLM) 执行更好的提取,以及这种新方法如何达到最先进 (SOTA) 的性能。
当前基准的问题
要理解 TKGT 的创新之处,我们首先需要看看该领域缺少什么。直到现在,研究人员主要依赖像 Wikitabletext or WikiBio 这样的数据集。这些数据集通常涉及描述单个实体 (如人物或体育比赛) 的短文本 (通常在 100 字以下) 。目标通常是从表格生成简短的描述 (表格到文本) ,反之亦然。
然而,这些数据集是“扁平”的。它们缺乏专业领域中存在的结构复杂性。论文作者进行了统计分析,以可视化这种差距。他们观察了文本中出现频率最高的词与表格中目标字段之间的相似度。
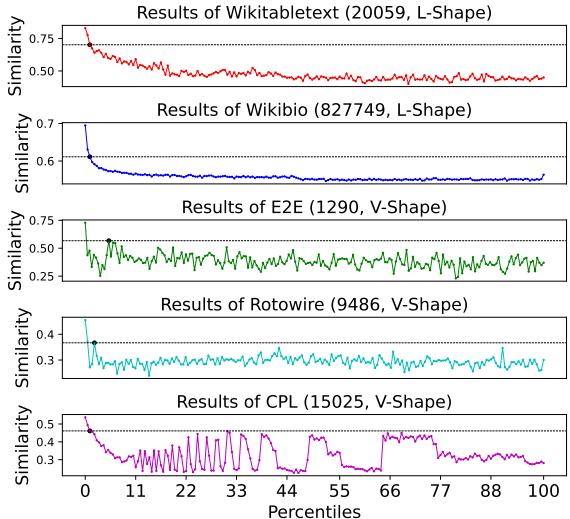
如图 1 所示,结果令人震惊:
- L型 (前两个图表) : 像 Wikitabletext 和 WikiBio 这样的数据集显示出简单的下降趋势 (L型) 。这表明一旦越过开头非常明显的关键词,其余文本中几乎没有隐藏结构信息。文本本质上只是事实的罗列。
- V型 (底部图表) : 相比之下,像 Rotowire (体育摘要) 和新的 CPL 数据集 (法律判决) 这样的复杂数据集显示出 V型 。 相似度下降,但随后反弹并震荡。这表明这些文本有一个“骨架”——一种深层结构,有价值的信息分散在整个文档中,通常与看起来不像字段名称但在理解逻辑上至关重要的结构性词汇混合在一起。
现实世界的文档,尤其是社会科学领域的文档,遵循这种 V 型模式。它们冗长、合乎逻辑且半结构化。像处理简单的维基百科摘要一样处理它们,正是以前的方法失败的原因。
介绍 CPL 数据集
为了解决缺乏现实基准的问题,研究人员引入了 CPL (Chinese Private Lending,中国民间借贷) 数据集。该数据集源自一个涉及中国判决文书的真实法律学术项目。
与描述一个人的传记不同,法律判决是一个涉及多个实体相互作用的 事件 。
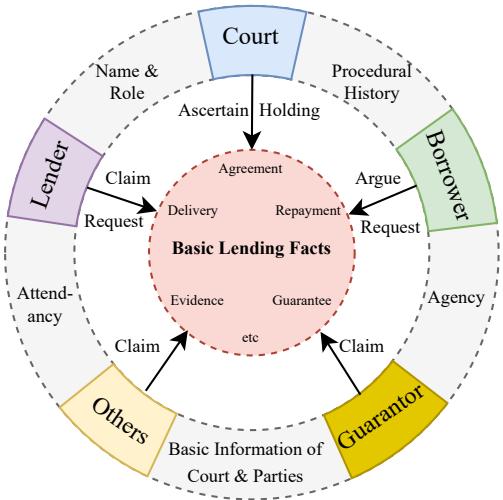
图 2 展示了 CPL 数据集的复杂性。它不仅仅是一个扁平的属性列表。它是一个关系网:
- 核心: “基本借贷事实” (协议、还款、担保) 。
- 实体: 法院、出借人、借款人、担保人和其他人。
- 交互: 出借人提出关于还款的诉讼请求;法院提供关于协议的认定。
文本本身很长 (平均每篇文档超过 1,100 字) ,并且以专业的法律格式撰写。

图 6 显示了源文本的一个示例。它包含程序历史、关于金钱的具体主张、借款人提出的抗辩以及最终的法院裁决。要从中提取一个干净的表格,需要理解“原告主张 X”与“法院裁决 X”是不同的,即使它们讨论的是同一笔金额。这个数据集是新方法的试验场。
核心方法: TKGT (Text-KG-Table)
研究人员提出,我们不能简单地将一份 2,000 字的法律文件输入 LLM 并要求输出表格的 JSON。上下文太多了,模型会产生幻觉或遗漏细节。
相反,他们提出了 TKGT , 这是一个利用 知识图谱 (KGs) 作为“中间件”的管道。其核心思想是首先将文本结构映射到 KG 模式 (Schema) 中,然后利用该模式精确地提取数据到表格中。

如图 3 所示,该管道由两个不同的阶段组成:
- 混合信息抽取 (Mixed-IE) 辅助的 KGs 生成: 为领域创建“蓝图” (模式) 。
- 基于混合 RAG 的表格填充: 使用该蓝图检索数据并填充表格单元格。
让我们详细分解这些步骤。
第一阶段: 混合信息抽取辅助的 KG 生成
在这个阶段,目标还不是提取具体的姓名或金额,而是定义我们要寻找什么 。 我们需要构建一组类 (例如,“原告”、“被告”、“贷款合同”) 和关系。
作者意识到,仅仅依靠 LLM 来“猜测”模式往往会失败。因此,他们使用了一种 混合信息抽取 (Mixed-IE) 方法:
- 规则 (Rule-based) : 他们利用文档的固有结构。例如,法律判决书通常有固定的部分 (标题、事实认定、说理、判决结果) 。
- 统计: 他们分析词频 (TF) 和文档频率 (DF)。在许多文档的特定部分频繁出现的词很可能是关键的结构字段 (例如,“利率”、“本金”、“担保”) 。
- LLM 优化: 这些统计关键词和基于规则的部分被输入到 LLM (如 LLaMA-3) 中。LLM 利用其内部知识将这些关键词组织成连贯的 KG 模式 (类和关系) 。
这是一个 半自动 的过程。人类专家可以审查 KG 模式草案并进行优化。这种“人在回路 (Human-in-the-loop) ”的方式确保了高质量的字段定义,而无需人类手动阅读数千份文档。
第二阶段: 基于混合 RAG 的表格填充
一旦定义了 KG 模式 (类和预期字段) ,系统就会进入提取阶段。这就是 混合检索增强生成 (Hybrid-RAG) 发挥作用的地方。
标准的 RAG 根据与查询的相似度检索文本块。然而,TKGT 做得更聪明。它利用 KG 结构生成 动态提示词 。
提取逻辑
系统遍历 KG 中定义的实体。它会问: “我们要找借款人的名字吗?”如果没有,它会生成一个特定的查询来查找它。
至关重要的是,提示词不是静态的。它是根据上下文动态重写的。

如图 7 所示,系统使用 查询重写提示词 (Query Rewrite Prompt) 。 如果系统正在寻找特定的目标 (例如,“还款金额”) ,它不会仅仅搜索“还款金额”。它使用 KG 中的实体描述来制定精确的查询: “编写一个查询以提取被告 X 的还款金额。”
然后将检索到的上下文传递给 信息检索提示词 (Information Retrieving Prompt) 。

在图 8 中,我们看到了最后一步。LLM 会收到:
- 角色 (例如,借款人) 。
- 属性 (例如,出生日期) 。
- 相关上下文 (通过上一步检索到的) 。
- 问题 (“…的值是什么?”) 。
这种有针对性的问答方法比要求 LLM 一次性生成一个巨大的表格要准确得多。它将模型的注意力集中在表格的一个特定单元格上,并由文本中找到的证据提供支持。
实验与结果
这个复杂的两阶段管道真的比直接让 GPT-4 做得更好吗?实验表明答案是肯定的。
评估第一阶段: KG 生成
首先,研究人员测试了他们的方法在定义表格结构 (字段和表头) 方面与纯 LLM 方法的对比。
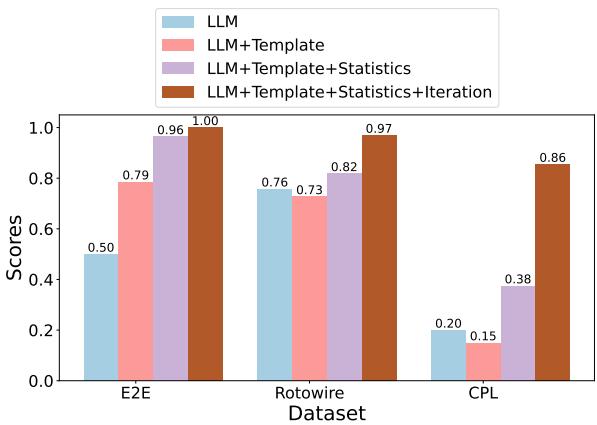
图 4 比较了四种方法:
- LLM: 要求模型零样本猜测字段。
- LLM + 模板: 给模型一些示例。
- LLM + 模板 + 统计: 添加统计关键词 (Mixed-IE) 。
- LLM + 模板 + 统计 + 迭代: 允许人工反馈。
结果表明,添加统计洞察显著提升了性能,尤其是在像 CPL 这样的复杂数据集上。纯 LLM 很难在复杂的法律文本中识别出正确的字段,往往会遗漏统计频率列表所揭示的关键细微差别。
评估第二阶段: 表格填充
最终的测试是用正确的数据填充表格。研究人员将 TKGT (使用较小的微调模型 ChatGLM3-6B) 与使用朴素 RAG 的大型商业模型 (如 GPT-3.5 和 GPT-4) 进行了比较。
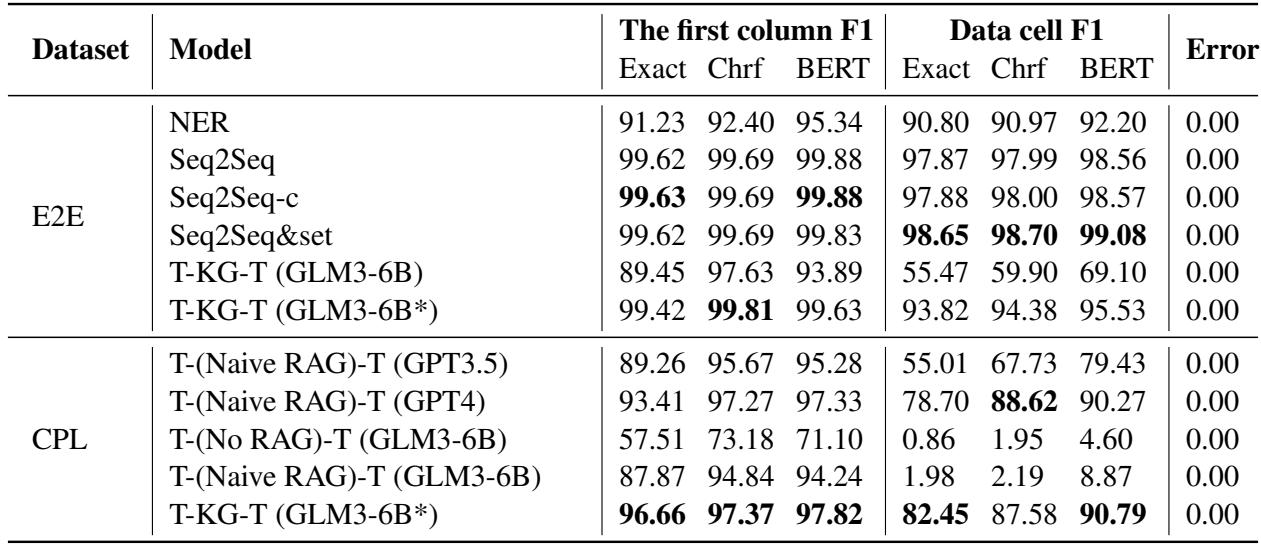
表 5 展示了在 CPL 数据集上的结果。使用的指标是 第一列 (The first column) (正确识别行/实体) 和 数据单元格 (Data cell) (正确获取值) 的 F1 分数。
- 商业 LLM: 使用朴素 RAG 的 GPT-4 实现了 88.62 的数据单元格 F1 分数。这相当不错,反映了 GPT-4 的能力。
- TKGT: TKGT 方法使用小得多的微调模型 (ChatGLM3-6B*) ,实现了 87.58 的数据单元格 F1 分数,这与 GPT-4 具有竞争力,并且显着击败了 GPT-3.5 (后者仅得分 67.73) 。
- 关键差异: 看看 第一列 F1 。 TKGT 得分为 96.66 , 击败了 GPT-4 的 93.41 。 这意味着 TKGT 更擅长将数据与正确的实体对齐——这在法律文件中是一个关键要求,因为混淆“原告”和“被告”是灾难性的错误。
对于 Rotowire 数据集 (体育) ,TKGT 在表头生成方面取得了满分,解决了一个常见问题,即模型生成的表格形状或列错误。
结论与启示
TKGT 论文提出了一个令人信服的观点: 当处理现实世界的混乱时,我们不能依赖“黑盒”式的端到端生成。
通过重新定义文本到表格的任务以适应长篇、半结构化文档,研究人员使该领域更接近实际应用。 CPL 数据集的引入为高难度提取任务提供了一个急需的基准。
最重要的是, TKGT 管道 证明了结构的重要性。通过首先使用统计方法构建 知识图谱模式 , 我们为 LLM 提供了一个路线图。该路线图允许精确的、RAG 驱动的提取,其性能优于大型通用模型,特别是在正确对齐实体方面。
对于进入该领域的学生和研究人员来说,结论很明确: 混合系统更胜一筹。 这种混合系统不仅利用了 LLM 的推理能力,还结合了知识图谱的结构和统计分析的精确性,创造了一个大于各部分之和的系统。这就是数字人文和计算社会科学的未来——将混乱的文本转化为清晰的结构化数据。