](https://deep-paper.org/en/paper/file-3698/images/cover.png)
想象一下,你为一家电子商务平台部署了一个客户支持聊天机器人。最初,它只用英语执行一项特定任务——跟踪订单。随着时间的推移,你的需求增加了。你需要增加西班牙语支持。接着,你需要增加“退货和退款”功能。随后,你又扩展到了印地语和阿拉伯语。
在传统的机器学习工作流程中,每当你增加一种新语言或一个新任务时,为了确保模型不会丧失其原有的能力,你可能需要用所有数据从头开始重新训练它。如果你只在新的西班牙语数据上对其进行微调,它可能会突然忘记如何说英语。如果你在“退货”数据上训练它,它可能会忘记如何跟踪订单。这种现象被称为灾难性遗忘 (Catastrophic Forgetting) 。
虽然研究人员已经研究了如何按顺序添加任务 (任务增量学习) 或按顺序添加语言 (语言增量学习) ,但这两者复杂的交集——任务与语言增量持续学习 (Task and Language Incremental Continual Learning, TLCL)——在很大程度上仍未被探索。
在这篇文章中,我们将深入探讨一篇题为 “TL-CL: Task And Language Incremental Continual Learning” 的论文,该论文提出了一个新的框架和一种称为 TLSA (Task and Language-Specific Adapters,任务和语言特定适配器) 的方法。这种方法允许模型高效地学习任务和语言矩阵,以线性而非多项式级数扩展,且无需存储 PB 级的历史数据。
问题所在: 任务与语言的矩阵
要理解这篇论文的创新之处,我们需要先定义持续学习 (Continual Learning, CL) 的领域。CL 指的是在不遗忘先前学到的信息的前提下,利用新数据更新模型的实践。
在自然语言处理 (NLP) 的背景下,这通常发生在两个维度上:
- 任务增量 (Task Incremental, TICL): 模型学习新的能力 (例如,情感分析 \(\rightarrow\) 问答 \(\rightarrow\) 摘要) ,所有任务都使用同一种语言。
- 语言增量 (Language Incremental, LICL): 模型学习用新的语言执行相同的任务 (例如,英语 \(\rightarrow\) 西班牙语 \(\rightarrow\) 印地语) 。
然而,现实世界的应用很少按直线发展。它们是在网格中移动的。你可能需要在一个现有的语言中增加一个新任务,或者为一个现有的任务增加一种新语言,或者在一个全新的语言中增加一个全新的任务。
作者用下图精美地展示了这种复杂性:
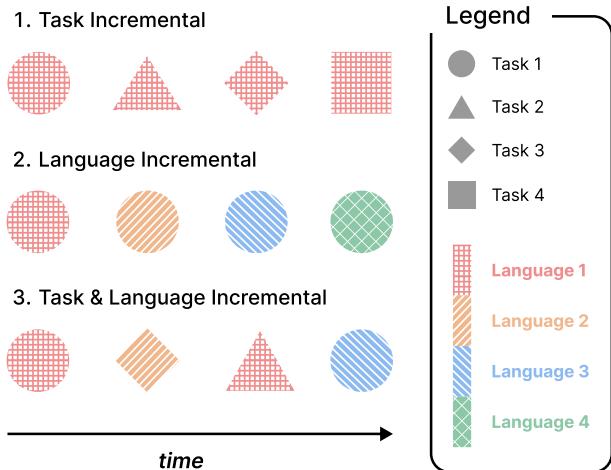
如 Figure 1 所示:
- 第 1 行 (任务增量) : 我们看到不同的形状 (任务) 按顺序出现,但纹理 (语言) 保持为“红色网格”。模型在语言 1 中先学习任务 1,然后是任务 2,依此类推。
- 第 2 行 (语言增量) : 我们连续看到相同的形状 (任务) ,但内部图案在变化。模型先学习语言 1 中的任务 1,然后是语言 2 中的任务 1,等等。
- 第 3 行 (任务与语言增量 - TLCL) : 这是论文的重点。新形状和新图案同时出现。我们可能会学习红色的圆形 (任务 1/语言 1) ,然后是橙色的菱形 (任务 3/语言 2) 。
TLCL 的目标是更新一个预训练的多语言模型 (如 mT5) ,以处理这些源源不断的任务-语言对,同时最大限度地减少灾难性遗忘并最大化知识迁移。
提出的解决方案: 任务和语言特定适配器 (TLSA)
微调大型模型 (如 BERT 或 T5) 的标准方法计算成本很高。为每个新任务重新训练所有参数速度很慢,且需要海量存储。这导致了参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT) 的兴起,即冻结巨大的预训练模型,只训练插入层与层之间的小型“适配器 (Adapter)”模块。
然而,标准适配器在 TLCL 设置中有一个缺陷。如果你为每一个“任务-语言”对训练一个特定的适配器 (例如,一个用于英语-QA,另一个用于西班牙语-QA,再一个用于印地语-NLI) ,你会面临两个问题:
- 多项式增长: 如果你有 \(|T|\) 个任务和 \(|L|\) 种语言,你需要 \(|T| \times |L|\) 个适配器。随着规模扩大,这将变得难以管理。
- 有限的迁移: 专门为“英语问答”训练的适配器不容易将其“问答”知识共享给西班牙语,也不容易将其“英语”知识共享给摘要任务。
作者提出了 任务和语言特定适配器 (TLSA) 。
架构
TLSA 的核心洞察是将任务知识与语言知识解耦 。 他们不是使用一个整体的适配器,而是在 Transformer 层中插入两种不同类型的适配器:
- 任务特定适配器 (\(\theta_t\)): 捕捉任务的逻辑 (例如,如何从上下文中提取答案) ,而不管语言如何。
- 语言特定适配器 (\(\theta_l\)): 捕捉语言的语法和词汇,而不管任务是什么。
这种分离改变了复杂性。当新任务到来时,你可以重用现有的语言适配器。当新语言到来时,你可以重用现有的任务适配器。
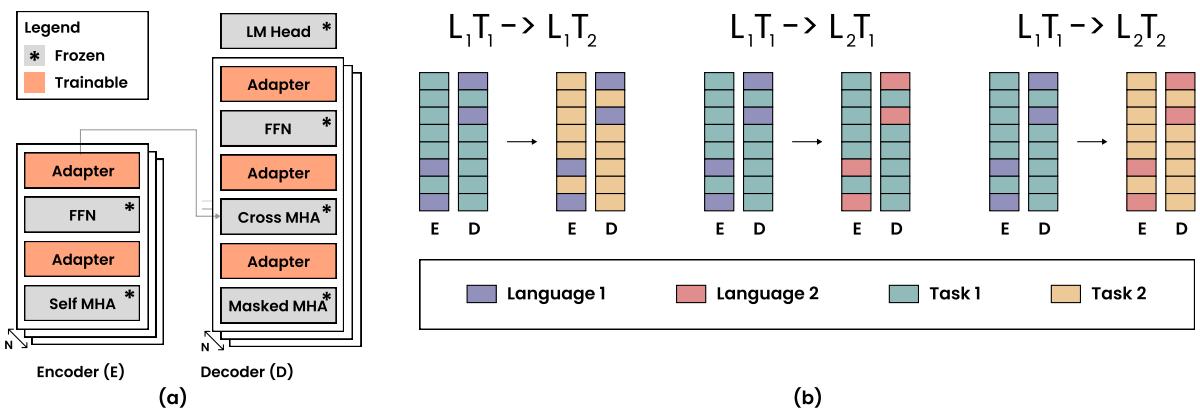
上面的 Figure 2 说明了这一机制:
- 部分 (a): 显示适配器位于 Transformer 编码器和解码器层内部的位置。注意任务适配器 (橙色) 和语言适配器 (此处未显式着色,但暗示为独立模块) 如何改变数据流向。
- 部分 (b): 这是关键逻辑。
- \(L_1T_1 \rightarrow L_1T_2\): 相同语言,新任务。我们保持语言适配器冻结 (紫色条) ,并交换/训练任务适配器 (青色变为黄色) 。
- \(L_1T_1 \rightarrow L_2T_1\): 相同任务,新语言。我们保持任务适配器冻结 (青色) ,并交换/训练语言适配器 (紫色变为粉色) 。
- \(L_1T_1 \rightarrow L_2T_2\): 两者都变。我们交换两者。
数学目标
为了训练这些适配器而不发生遗忘,仅仅分离它们是不够的。作者采用了 弹性权重巩固 (Elastic Weight Consolidation, EWC) 。 EWC 是一种正则化技术,它会对模型改变那些对先前任务很重要的参数进行惩罚。
当针对特定任务 \(t\) 和语言 \(l\) 进行训练时,目标函数如下所示:


让我们分解一下这个方程:
- 损失 (\(\mathcal{L}\)): 第一部分
argmin旨在最小化当前数据集 \((X^{t,l}, Y^{t,l})\) 上的标准误差。它使用基础模型参数 \(\theta_b\) (冻结) 、任务适配器 \(\theta_t\) 和语言适配器 \(\theta_l\)。 - 正则化 (概念) : \(\alpha\) 之后的项是 EWC 正则化。
- 如果任务 \(t\) 之前出现过 (\(t \in S_{tasks}\)) ,我们添加一个惩罚项 \(R(\theta_t, \theta_t^*)\)。这可以防止任务适配器偏离其在先前会话中学到的最佳状态 \(\theta_t^*\) 太远。
- 同样,如果语言 \(l\) 之前出现过 (\(l \in S_{langs}\)) ,我们使用 \(R(\theta_l, \theta_l^*)\) 来惩罚对语言适配器的更改。
这使得模型具有“弹性”——它可以弯曲以学习新数据,但如果它离旧任务所需的知识太远,它会弹回来。
为什么这很重要: 线性复杂度
TLSA 最显著的理论优势是效率。
- 参数隔离 (标准) : 需要 \(|T| \times |L|\) 个适配器。如果你有 10 个任务和 10 种语言,你需要管理 100 组适配器。
- TLSA: 需要 \(|T| + |L|\) 个适配器。对于 10 个任务和 10 种语言,你只需要管理 20 组适配器。
这种线性增长 (\(O(|T| + |L|)\)) 使得 TLSA 对于大型多语言系统具有高度的可扩展性。
实验设置
为了证明 TLSA 的有效性,研究人员建立了一个严格的基准测试。
模型: 他们使用 mT5-small (Multilingual T5) 作为骨干网络。 任务:
- 分类 (cls): 情感分析。
- 自然语言推理 (nli): 判断语句是矛盾还是蕴含。
- 问答 (qa): 基于上下文的提取。
- 摘要 (summ): 生成摘要。
语言: 英语 (en)、西班牙语 (es)、印地语 (hi)、阿拉伯语 (ar)。
场景: 他们不仅测试了一个简单的序列。他们设计了三个难度级别:
- 完整的任务-语言序列: 所有任务和语言的组合都有数据。
- 部分任务-语言可用性: 缺少某些组合 (例如,你可能有英语-QA,但没有印地语-QA) 。
- 单一语言约束: 最难的设置。没有任务或语言会立即重复。
结果与分析
作者将 TLSA 与几个强基线进行了比较:
- SFT: 顺序微调 (朴素方法,容易遗忘) 。
- EWC: 全模型上的正则化。
- ER: 经验回放 (存储旧数据缓冲区进行排练) 。
- MAD-X: 另一个基于适配器的框架。
- TSA: 任务特定适配器 (仅分离任务,不分离语言) 。
- TLSA (本文提出) : 上述方法。
- TLSA\(_{PI}\): 使用参数隔离的 TLSA 变体 (为每对组合保存适配器副本——零遗忘但内存占用更高) 。
性能比较
使用的主要指标是 PercentLoss (百分比损失) , 它衡量持续学习模型与一次性训练所有内容的模型 (上限) 相比差了多少。 数值越低越好。
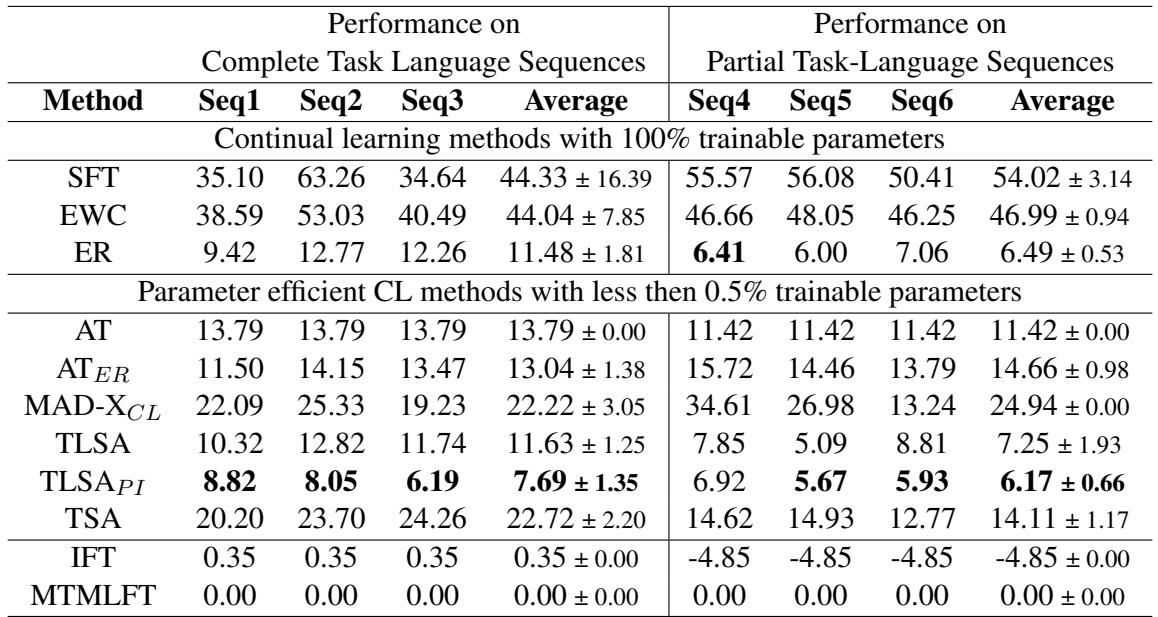
查看 Table 1 , 我们可以得出几个关键结论:
- 朴素 SFT 失败了: 约 44% 的 PercentLoss 意味着简单的微调遗忘了它相对于上限所学内容的近一半。
- ER 很强: 经验回放 (ER) 表现出色 (11.48% 损失) 。重播旧数据是提醒模型过去的有力方式,但这伴随着保存数据的“隐私和存储成本”。
- TLSA 统领 PEFT: 在不使用回放或保存无限适配器副本的参数高效方法中, TLSA (11.63%) 是赢家。它的表现几乎与经验回放相当。
- TLSA\(_{PI}\) 是冠军: 如果你愿意存储单独的适配器状态 (参数隔离) ,TLSA\(_{PI}\) 实现了最低的损失 (7.69%)。
交叉迁移有效吗?
TLSA 的主要主张之一是分离任务和语言将允许更好的迁移。例如,学习英语的“问答”应该改善“问答”适配器,进而有助于学习印地语的“问答”。
作者通过消融实验验证了这一点:
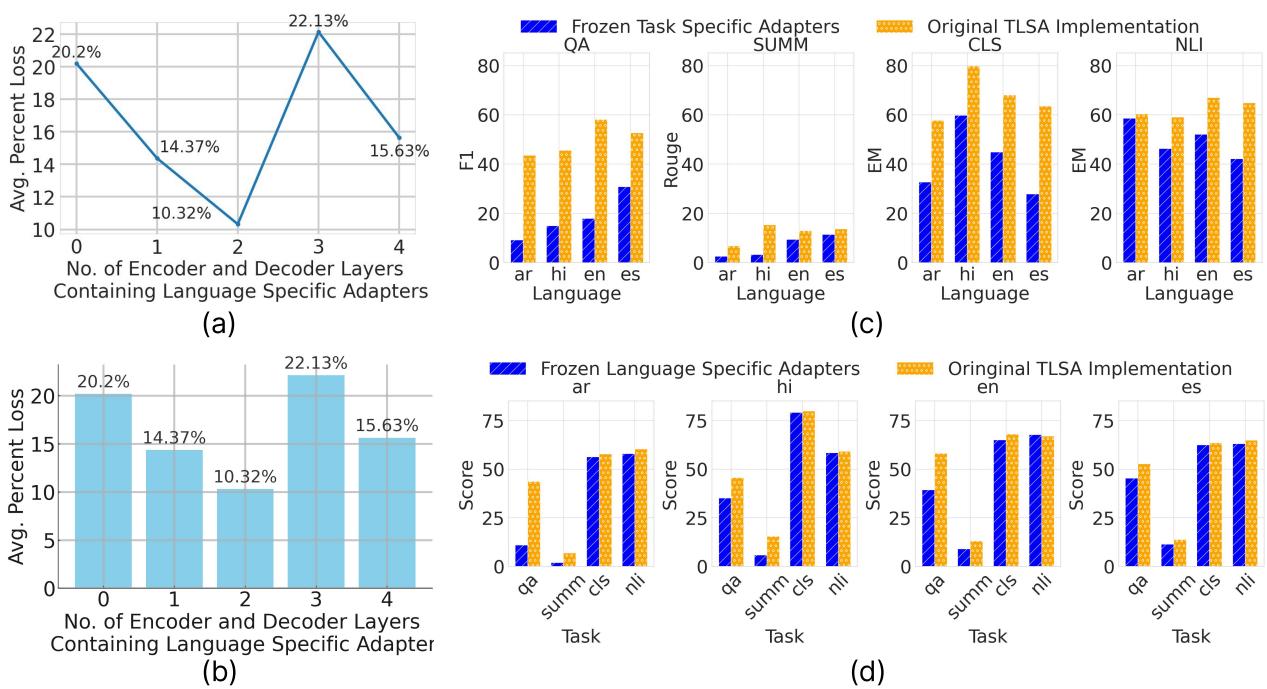
关注 Figure 3 中的 Chart (c) 和 Chart (d) :
- Chart (c) - 跨语言迁移: 作者取了一个预训练的任务适配器并将其冻结,然后将其应用于新语言 (蓝色条) 。他们将其与完整的 TLSA 训练 (橙色条) 进行了比较。在许多情况下,性能非常接近,证明了任务适配器成功捕获了迁移到新语言的语言无关技能。
- Chart (d) - 跨任务迁移: 同样,他们冻结了语言适配器并将其应用于新任务。高性能表明语言适配器成功封装了独立于手头特定任务的语言句法。
零样本限制
虽然 TLSA 在增量学习方面表现出色,但这篇论文也调查了“零样本泛化”——将模型应用于它从未见过的任务-语言对 (例如,在英语-QA 和西班牙语-NLI 上训练,然后在西班牙语-QA 上测试) 。
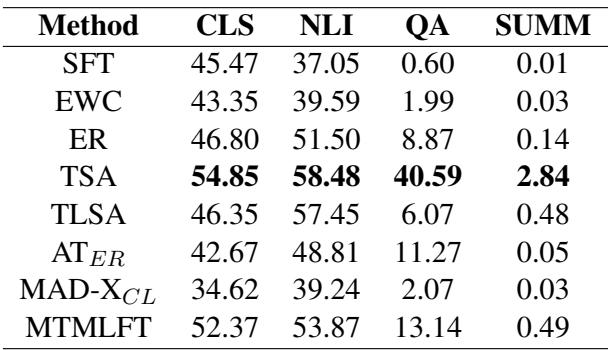
如 Table 3 所示,大多数方法在这里都很吃力。虽然在分类 (CLS) 和 NLI 等较简单的任务上性能尚可,但在 QA 和摘要任务上性能显著下降。作者指出,模型产生了强烈的 token 偏差。例如,如果一个模型仅在 NLI 的上下文中看到西班牙语,它就很难生成西班牙语摘要,因为它的“西班牙语表示”过拟合了 NLI 的格式。这仍然是该领域的一个开放挑战。
结论
论文 TL-CL 解决了一个现实且棘手的问题: 随着 NLP 模型扩展到新市场 (语言) 和新产品功能 (任务) ,如何持续更新它们。
提出的解决方案 TLSA 提供了一个优雅的架构修复。通过将“任务”和“语言”视为独立的模块化组件,我们可以:
- 减少内存增长: 从多项式复杂度降低到线性复杂度。
- 启用迁移: 利用英语 QA 知识来改进印地语 QA。
- 防止遗忘: 使用 EWC 保护这些模块化组件。
对于学生和从业者来说,TLSA 代表了我们对深度学习中模块化思考方式的转变。它表明,与其训练一个巨大的“黑盒”,不如将神经网络分解为语义组件 (如“语言”块和“任务”块) ,这是构建可扩展的终身学习系统的关键。
虽然经验回放仍然是一个强力的冠军,但 TLSA 证明,通过巧妙的架构,我们可以在没有历史数据沉重包袱的情况下实现可比的稳定性。