](https://deep-paper.org/en/paper/file-3702/images/cover.png)
TUNA: 利用检索增强标签解决多模态对齐差距
想象一下,给 AI 展示一张稀有奇异水果的照片,然后问: “这是什么?”如果 AI 在微调阶段看过数百万张苹果和香蕉的照片,却从未见过这种特定的水果,它可能会自信地告诉你这是“石榴”,或者干脆产生看似合理但在视觉上错误的描述幻觉。
这是多模态大语言模型 (MLLMs) 中普遍存在的一个问题。虽然像 LLaVA 这样的模型彻底改变了计算机理解图像的方式,但在处理详细的视觉指令时,它们经常在三个具体问题上遇到困难:
- 识别新颖物体 (不在其指令微调数据中的事物) 。
- 幻视不存在的物体 (明明没有刀却说有) 。
- 遗漏具体细节 (忽略颜色或纹理等属性) 。
在这篇文章中,我们将深入探讨一篇题为 “Tag-grounded Visual Instruction Tuning with Retrieval Augmentation” 的研究论文。作者介绍了 TUNA , 这是一个新颖的框架,通过使用巨大的外部“标签”存储器来弥合视觉理解和语言生成之间的差距。
问题所在: “对齐差距”
为了理解为什么需要 TUNA,我们需要先了解当前 MLLM 的失败之处。
请看下面的图片。它展示了一张山竹的照片。

正如你在 图 1 中看到的那样,像 GPT-4 和 LLaVA 这样的标准模型表现挣扎。GPT-4 识别出了水果,但遗漏了刀的背景。LLaVA-Wild 完全失败,将水果识别为“石榴”,并幻视出了根本不存在的“碗”和“勺子”。本文提出的模型 (Ours) 正确识别了山竹和刀。
为什么会发生这种情况?
根本原因在于这些模型的架构。大多数 MLLM 由两个主要部分组成:
- 视觉编码器 (如 CLIP) : 它负责读取图像。它在数亿对图像-文本对 (例如 4 亿) 上进行了预训练。它“认识”什么是山竹,因为它在海量数据集中见过。
- 多模态连接器与 LLM: 这部分负责将视觉特征转化为语言。然而,这个连接器通常是在一个小得多的数据集 (例如 120 万对) 上进行微调的。
这里存在不匹配。视觉编码器看到了“山竹”的特征,但连接器还没有学到将这些特定视觉特征映射到语言模型空间中“山竹”一词的“词汇量”。作者将此称为 对齐差距 (alignment gap) 。
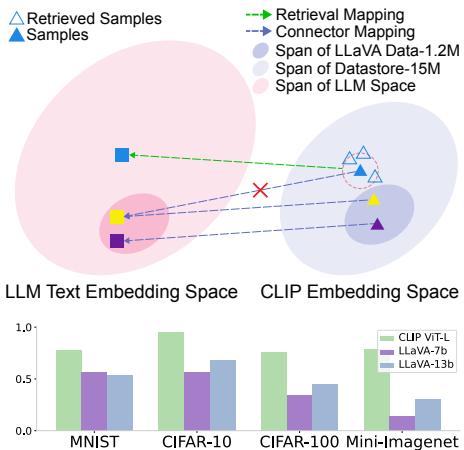
图 2 完美地阐释了这一点。
- 上图: 粉色区域代表模型微调所用的数据。蓝色三角形代表一个新的、“分布外” (OOD) 物体 (如山竹) 。连接器试图对其进行映射,但错过了目标 (文本嵌入) ,落在了黄色方块而不是绿色三角形上。
- 下图: 条形图显示,虽然冻结的 CLIP 编码器 (绿色条) 在图像分类方面具有很高的准确率,但在其之上构建的 MLLM (紫色和蓝色条) 实际上分类能力变 差 了。连接器成了瓶颈,导致信息丢失。
解决方案: TUNA
研究人员提出了一种受检索增强生成 (RAG) 启发的解决方案。如果模型不“知道”某个图像对应的单词,为什么不让它去查一下呢?
TUNA 代表 Tag-grounded Visual Instruction tUNing with retrieval Augmentation (基于标签的检索增强视觉指令微调) 。TUNA 不仅依赖训练中学到的权重,还从外部数据库中检索相关的“标签” (关键词) 来帮助指导生成过程。
第一步: 构建数据存储 (挖掘标签)
检索完整的标题可能会带来很多噪声。标题通常很长、口语化或不相关。作者意识到 标签——具体的名词和属性——是视觉定位更清晰的锚点。
为了构建数据存储,他们从 CC12M 和 CC3M 等数据集中提取了 1500 万个图像-文本对。他们不仅使用了标题;还使用场景图解析 (Scene Graph Parsing) 和命名实体识别 (NER) 对其进行了处理。这从文本中提取了核心的“对象”和“属性”。

如图 图 3 所示,关于蒙特普齐亚诺街道的标题被提炼为精确的标签: “狭窄的街道”、“多彩的立面”、“蓝天”和“蒙特普齐亚诺”。这创建了一个巨大的索引,其中视觉嵌入是键,而这些精确的标签是值。
第二步: TUNA 架构
那么,模型在训练和推理过程中是如何使用这些标签的呢?让我们分解 图 4 中展示的架构。
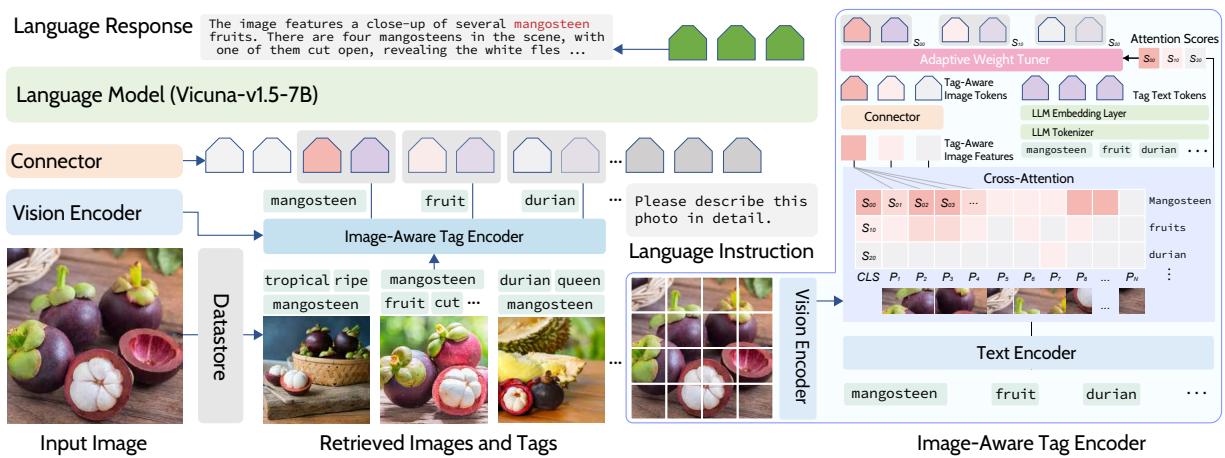
流程如下:
- 检索: 当输入图像到达时,系统使用 CLIP 在外部数据存储中查找最相似的图像。
- 标签提取: 提取与这些检索到的图像相关联的标签。
- 图像感知标签编码器 (“秘方”) : 这是 TUNA 的亮点所在。它不仅仅将标签作为文本输入。它将标签通过一个特殊的编码器,该编码器会关注 原始输入图像。
- 如果检索到的标签是“猫”,编码器会检查输入图像: “这里真的有猫吗?这只特定的猫长什么样?”
- 这产生了一个 图像感知标签 token , 融合了单词的语义含义和当前图像的具体视觉特征。
- 自适应权重调节器: 并非所有检索到的标签都是好的。如果你有一张榴莲的照片,你可能会检索到一张波罗蜜的照片,因为它们看起来很像。你不希望模型输出“波罗蜜”。 自适应权重调节器 根据标签与输入图像的匹配程度计算一个分数。低相关性的标签会被降低权重,这样它们就不会混淆 LLM。
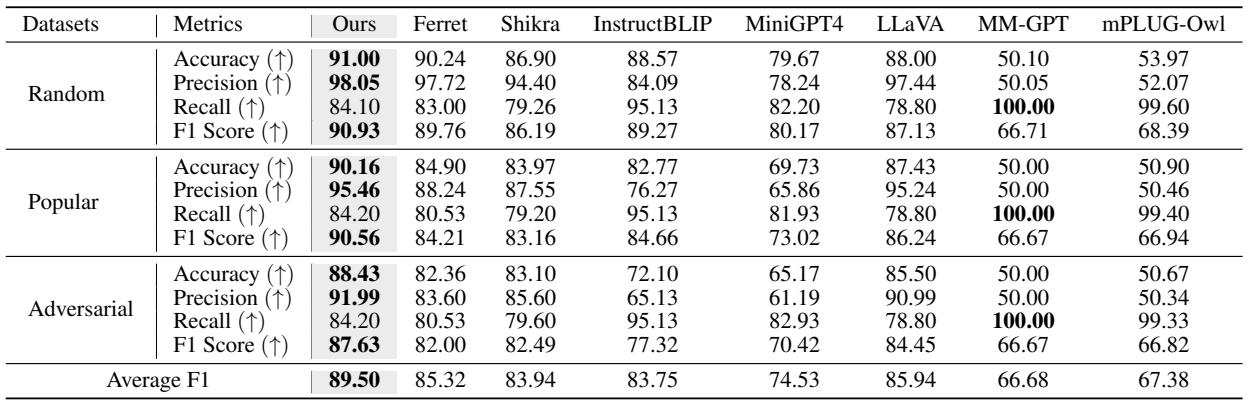
实验结果
研究人员在 12 个不同的基准测试中,将 TUNA 与 LLaVA-1.5、InstructBLIP 和 Qwen-VL 等最先进的模型进行了对比测试。
定量表现
结果是一致的: TUNA 优于使用相同底层语言模型 (Vicuna-7B) 和训练数据的基线模型。
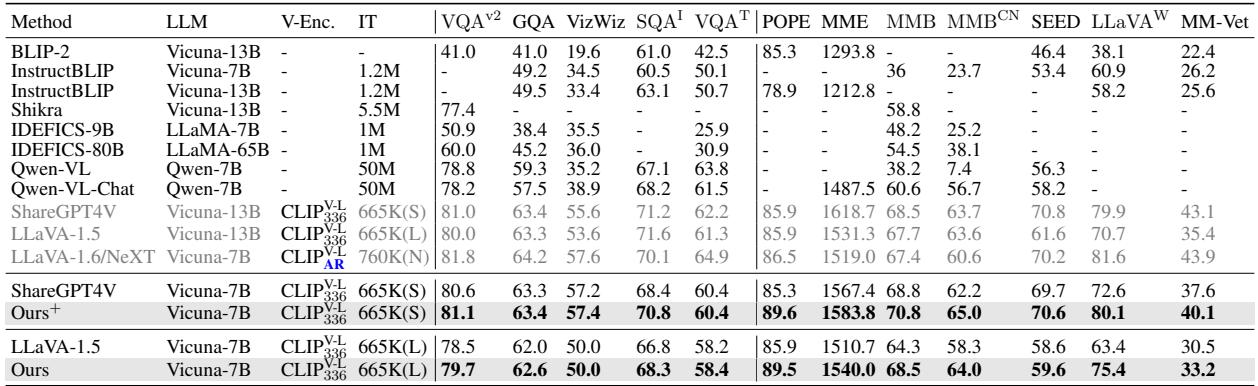
在 表 2 中,你可以看到 TUNA (Ours) 在 VQA (视觉问答) 、POPE (物体幻觉) 和 MME 等基准测试中取得了最高分。它甚至在几个类别中可以与更大的 13B 模型相抗衡。
减少幻觉
最显著的改进之一是在 POPE 基准测试中,该测试衡量物体幻觉 (模型是否会说某个物体存在,而实际上并不存在?) 。
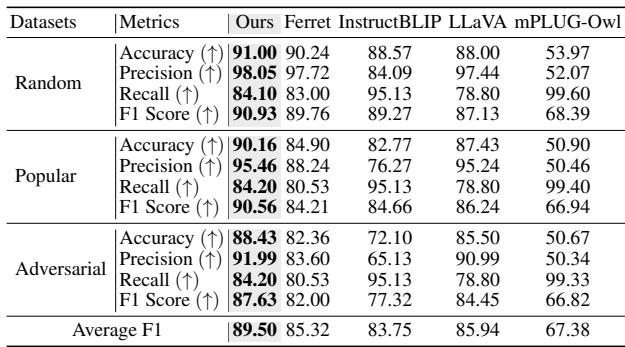
如 表 4 所示,TUNA 实现了比标准 LLaVA 甚至专为定位设计的模型 (如 Ferret) 更高的准确率和精确度。通过拥有基于图像的明确标签,模型不太可能进行错误的“猜测”。
定性示例: 眼见为实
数据虽好,但看到模型的实际运行情况更能解释 为什么 它效果更好。
识别艺术与现实
在下面 图 5 的顶部示例中,问题问道: “这件艺术品是以建筑形式存在的吗?” (意思是,这是真正的建筑物还是画作?) 。LLaVA 感到困惑并回答“是”。TUNA 检索了类似的画作图像,并正确回答“否”。
发现微小细节
在底部示例中,用户询问是否有单板滑雪板。这很难看清。TUNA 检索了滑雪和单板滑雪背景的图像,帮助它正确识别出“YES”,而 LLaVA 错过了它。注意“热力图”可视化——这显示了 自适应权重调节器 的工作情况。亮点表示模型信任的标签;暗点是它忽略的标签。

描述性细节
TUNA 不仅仅能回答是/否;它还能改进详细描述。在下面关于钻石头山 (Diamond Head crater) 的例子中,LLaVA 幻视出“船”和“人”,使场景听起来更通用。TUNA 坚持事实,正确描述了背景中的植被和房屋 (实际上确实存在) ,这很可能是由检索到的关于鸟瞰图和景观的标签提示的。

零样本能力: 时尚测试
也许 TUNA 最令人印象深刻的能力展示是它的 零样本 (zero-shot) 能力。研究人员使用 FashionGen 的图像创建了一个“Fashion-Bench”。他们没有在这个特定数据上微调 TUNA;他们只是简单地将外部数据存储库换成了包含时尚相关图像和标签的库。
因为 TUNA 学会了 使用 数据存储,它只需更改参考库即可立即适应新领域。
请看 图 9 。 输入是一个穿着特定图案西装外套的男人。
- LLaVA-1.5 给出了通用的描述: “带有白色圆点的黑色夹克”。它完全错过了品牌。
- TUNA 检索了类似的时尚单品。它正确识别了“白色星星图案” (不是圆点) ,甚至识别出了品牌为 Neil Barrett 。
这就是检索的力量。模型权重不需要记住现存的每一个时尚品牌;数据存储保存了这些知识,而 TUNA 知道如何获取它。
为什么选择标签而不是标题?
你可能会想: 为什么要费力提取标签?为什么不像标准 RAG 那样检索标题 (句子) 呢?
作者进行了一项消融研究来测试这一点。
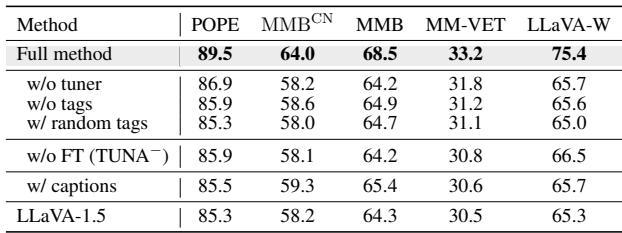
表 6 显示了结果。
- w/ captions (使用标题) : 使用完整句子实际上导致性能比使用标签 更低。标题包含可能分散模型注意力的噪声和语言结构。
- w/o tuner (无调节器) : 移除自适应权重调节器也会损害性能,证明你不能盲目相信每一个检索到的标签。
- w/o tags (无标签) : 这本质上是基线性能,明显较低。
结论
TUNA 论文提出了一个令人信服的论点,即多模态 LLM 应该超越简单的端到端训练。通过承认“对齐差距”——即利用有限的训练数据将每个可能的视觉概念映射到文本的困难——研究人员找到了一种利用外部知识来弥补这一差距的方法。
主要收获:
- 检索增强适用于视觉: 正如 LLM 受益于查找事实一样,MLLM 也受益于查找视觉概念。
- 标签优于标题: 精确的、面向对象的标签比嘈杂的句子能提供更好的定位信号。
- 自适应加权至关重要: 检索是不完美的;模型必须学会根据实际的视觉输入忽略不相关的检索数据。
TUNA 提供了一种轻量级、有效的方法,使 AI 模型更精确、更不容易产生幻觉,并且能够在无需昂贵的重新训练的情况下适应像时尚这样的新领域。这是朝着能够如实观察和描述世界的 AI 迈出的重要一步。