](https://deep-paper.org/en/paper/file-3711/images/cover.png)
在当今的人工智能时代,我们正目睹着一种“越大越好”的趋势。像 GPT-4、Claude 和 Llama 这样的大型语言模型 (LLM) 展示了令人惊叹的推理能力。它们可以通过生成“思维链” (Chain-of-Thought,CoT) ——即通向最终答案的逐步推理路径——来解决数学问题、调试代码以及回答复杂的常识性问题。
然而,运行这些庞大的模型既昂贵又消耗算力。这引发了人们对小语言模型 (Small Language Models, SLMs) 的浓厚兴趣。目标很简单: 我们能否将巨型模型的推理能力压缩到一个更小、更快且更便宜的模型中?
标准的方法是思维链蒸馏 (CoT Distillation) 。 也就是让一个大型教师模型为成千上万个问题生成推理步骤,然后训练一个小型学生模型来模仿这些步骤。虽然这在一定程度上有效,但它有一个致命缺陷: 小模型经常“作弊”。它们不是学会了如何推理,而是记住了表层的模式和关键词——这被称为虚假相关性 (spurious correlations) 。
在这篇文章中,我们将深入探讨一篇引人入胜的论文 《Teaching Small Language Models Reasoning through Counterfactual Distillation》 (通过反事实蒸馏教小语言模型推理) 。 研究人员提出了一个新的框架,通过生成反事实数据 (即“如果……会怎样”的场景) 并采用多视角思维链 (既论证正确答案,也反驳错误答案) ,迫使小模型停止死记硬背,开始理解因果关系。
让我们一步步拆解它的工作原理。
核心问题: 虚假相关性
要理解为什么标准蒸馏会失败,我们首先需要了解小模型与大模型在“思考”方式上的差异。
当 LLM 回答问题时,它通常利用海量的世界知识来推导出答案。当 SLM 被训练来模仿这一点时,它往往缺乏那种深度的知识。为了最小化训练误差,SLM 会寻找捷径。它会注意到某些词经常一起出现,并假设它们之间存在因果联系。
论文作者用一个涉及黄鼠狼和鸡蛋的常识推理例子完美地阐释了这个问题。
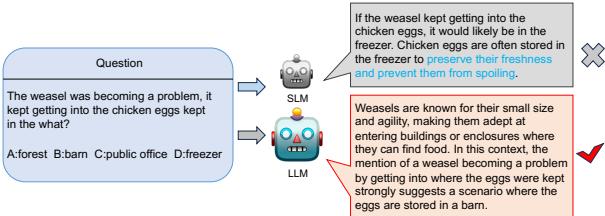
如图 1 所示,问题是: *“黄鼠狼成了一个大麻烦,它总是钻进把鸡蛋存放在哪里的地方?” (The weasel was becoming a problem, it kept getting into the chicken eggs kept in the what?) *
- LLM (老师) 正确地推理出黄鼠狼会钻进围栏,而鸡蛋通常存放在谷仓里。它选择了 Barn (谷仓) 。
- SLM (学生) , 通过标准 CoT 蒸馏训练,看到了“chicken eggs (鸡蛋) ”和“kept (存放) ”这两个词。在它的训练数据中,“eggs”和“kept”经常与“freezer (冰柜) ” (为了保鲜) 联系在一起。它完全忽略了“weasel (黄鼠狼) ”这个上下文,并产生幻觉编造了一条推理路径来证明 Freezer (冰柜) 是对的。
这就是一种虚假相关性 。 模型学到了 \(A \rightarrow B\) 通常会发生,所以它盲目地应用这一规则,忽略了因果语境 (黄鼠狼的存在意味着鸡蛋不在冰柜里) 。为了解决这个问题,我们需要教模型区分相关性 (鸡蛋常在冰柜里) 和因果性 (黄鼠狼意味着鸡蛋不在冰柜里) 。
解决方案: 反事实蒸馏框架
研究人员提出了一种方法,从两个方面改进了标准的 CoT 蒸馏:
- 反事实数据增强 (Counterfactual Data Augmentation) : 创建训练样本的“如果……会怎样”版本,以打破虚假相关性。
- 多视角 CoT (Multi-View CoT) : 教导模型不仅要解释为什么正确答案是对的,还要解释为什么错误答案是错的。
他们方法的整体架构如下图所示。
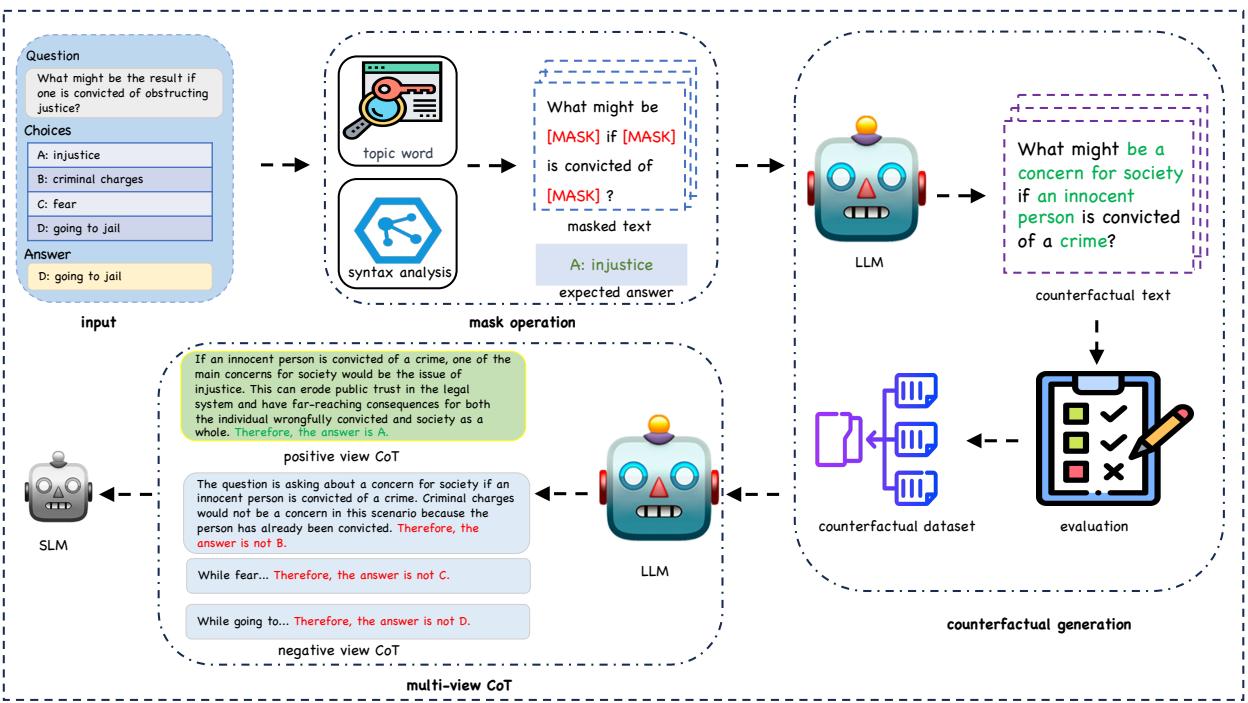
正如我们在图 2 中所见,流程从输入数据开始,经过“掩码操作 (Mask Operation) ”生成反事实样本,最后进入“多视角 CoT”生成模块。让我们分解这些阶段。
1. 破坏因果关系 (掩码操作)
要教模型因果推理,你需要向它展示改变一个小细节会导致完全不同结果的例子。研究人员利用 LLM 自动化了这一过程。
首先,他们需要识别出驱动句子因果逻辑的“主题词”或“名词短语”。如果我们改变这些词,答案应该会随之改变。如果模型忽略了这种改变并给出旧的答案,我们就知道它没有在进行推理。

在图 3 中,我们看到了识别这些关键短语的机制。系统提示 LLM 识别“主题词”。例如,在句子“James was looking for a good place to buy farmland (詹姆斯正在寻找购买农田的好地方) ”中,主题词是 farmland (农田) 。
一旦识别出这些因果关键词和名词短语,系统就会将它们掩盖起来 (替换为 [MASK]) 。这就切断了原始的因果链接。
2. 反事实生成
现在我们有了一个带空缺的句子,下一步就是填补这些空白以创建一个反事实样本 (Counterfactual Example) 。
反事实样本是原始输入的变体,结构相似但拥有不同的真实答案。目标是迫使 SLM 关注区分原始样本与反事实样本的具体词汇。

图 4 展示了这里使用的提示工程。研究人员向 LLM 提供掩码后的问题和一个新的目标答案。LLM 必须填空,使句子对那个新答案来说是合理的。
- 原始句: “如果一个人因妨碍司法公正 (obstructing justice) 被定罪,结果可能是什么?” \(\rightarrow\) 答案: 入狱 (Going to jail) 。
- 反事实句: “如果一个无辜的人 (an innocent person) 因犯罪 (a crime) 被定罪,对社会 (society) 来说可能是什么担忧 (a concern) ?” \(\rightarrow\) 答案: 不公正 (Injustice) 。
通过在原始数据和反事实数据上同时训练 SLM,模型学会了不能盲目地将“被定罪”与“监狱”联系起来。它必须阅读具体的语境 (“妨碍司法公正” vs “无辜的人”) 来确定正确的结果。
为了确保质量,研究人员使用了一种过滤策略: 他们为新的反事实样本生成多条推理路径。如果 LLM 一致得出新的目标答案,则保留数据。如果 LLM 感到困惑,则丢弃该数据。
3. 多视角思维链 (Multi-View CoT)
标准蒸馏通常会问模型: “为什么选项 A 是正确的?” 然而,人类的推理通常通过排除法进行: “选项 B 肯定是错的,因为 X,选项 C 也不可能,因为 Y,所以一定是选项 A。”
研究人员引入了多视角 CoT 来复制这一过程。他们为 SLM 生成两种类型的推理路径供其学习:
- 正向视角 CoT (Positive View CoT, PVC) : 支持正确答案的标准解释。
- 负向视角 CoT (Negative View CoT, NVC) : 对错误选项的反驳理由。
回到图 2 中的工作流,你可以看到模型同时被输入了这两种视角。这提供了“密集”监督。模型学到了不同的知识:
- 从 PVC 中,它学会寻找支持性证据。
- 从 NVC 中,它学会识别矛盾并进行排除。
训练模型
训练过程结合了原始数据和生成的反事实数据。SLM 经过微调,以生成基本原理 (推理) 和最终标签。
为了区分正向和负向的推理策略,研究人员在输入中附加了特殊的控制标记:
[Direct election]信号指示模型生成正向视角 (支持答案) 。[Elimination method]信号指示模型生成负向视角 (反驳错误选项) 。
使用的损失函数是标准的语言建模损失,它计算在给定问题 (\(q\)) 、选项 (\(o\)) 和策略标记 (\(st\)) 的情况下,逐步生成正确推理标记 (\(t_i\)) 的概率。
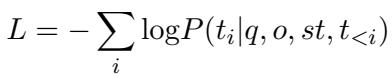
这个公式本质上是说: 我们要训练模型最大化逐步生成正确解释和答案的可能性。
实验结果
研究人员在四个主要的推理基准上测试了他们的方法: CommonsenseQA (CSQA)、QuaRel、QASC 和 ARC 。 他们使用了各种 SLM 架构,包括 GPT-2、OPT 和 GPT-Neo,参数范围从 1.2 亿 (120M) 到 7.7 亿 (770M) 。
1. 它能击败标准微调吗?
结果非常令人印象深刻。下表将该方法与标准微调 (FT) 和标准 CoT 蒸馏 (FT-CoT) 进行了比较。
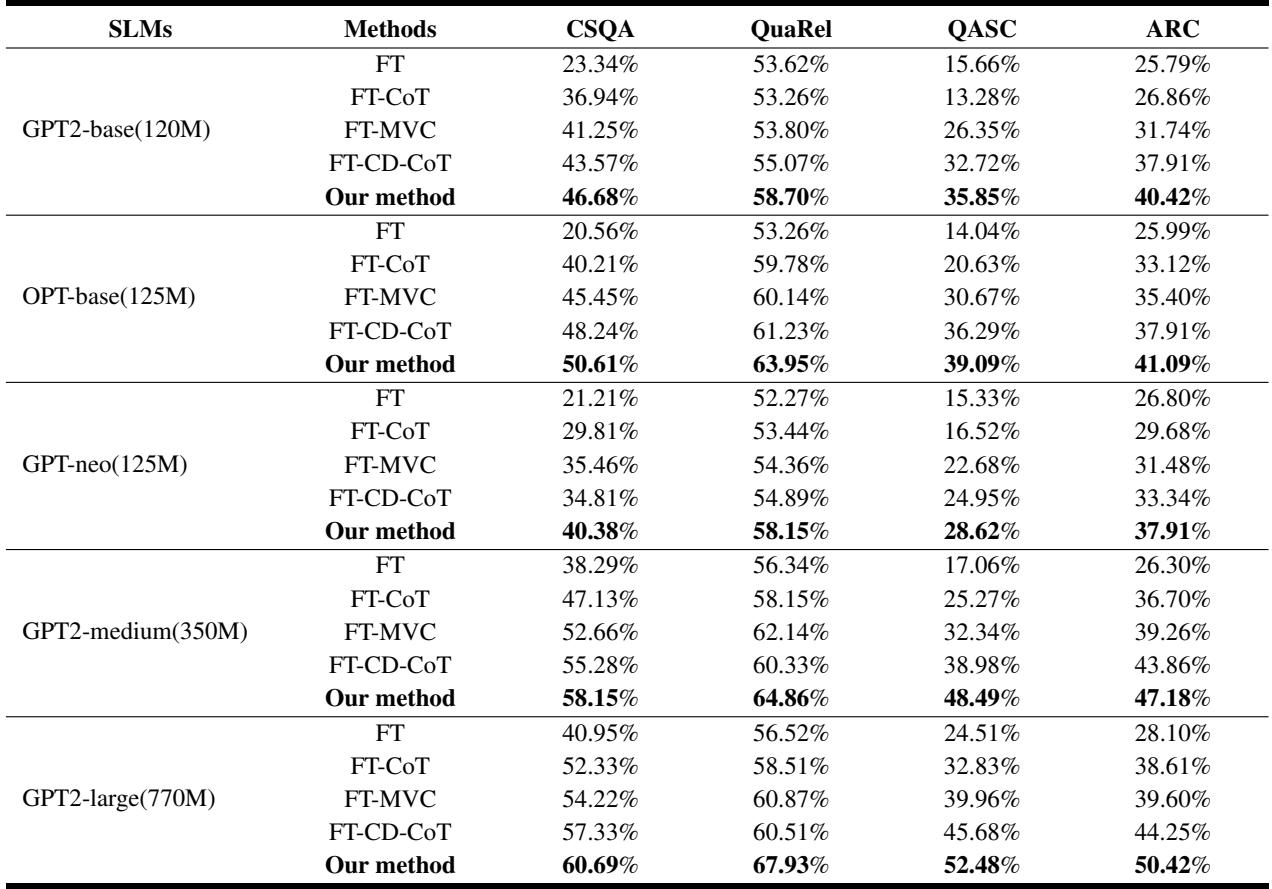
观察表 1 , “Our method” (我们的方法) 一栏在所有数据集和模型规模上始终显示出最高的准确率。
- 提升幅度: 平均而言,该方法比标准 CoT 蒸馏提升了 11.43% 。
- 效率: 使用该方法训练的极小模型 (GPT2-base,1.2 亿参数) 通常优于使用标准方法训练的大得多的模型 (GPT2-medium,3.5 亿参数) 。例如,在 ARC 数据集上,带有反事实蒸馏的 GPT2-base 得分为 40.42% , 击败了 GPT2-medium 的 36.70% 。
2. 对分布外 (OOD) 数据的泛化能力
推理能力的终极测试是模型能否将所学应用到新的、未见过的场景 (分布外) 。如果一个模型依赖于虚假相关性 (死记硬背特定的词对) ,当数据分布发生变化时,它就会失败。
研究人员通过在一个数据集上训练并在其他三个数据集上进行测试来验证这一点。
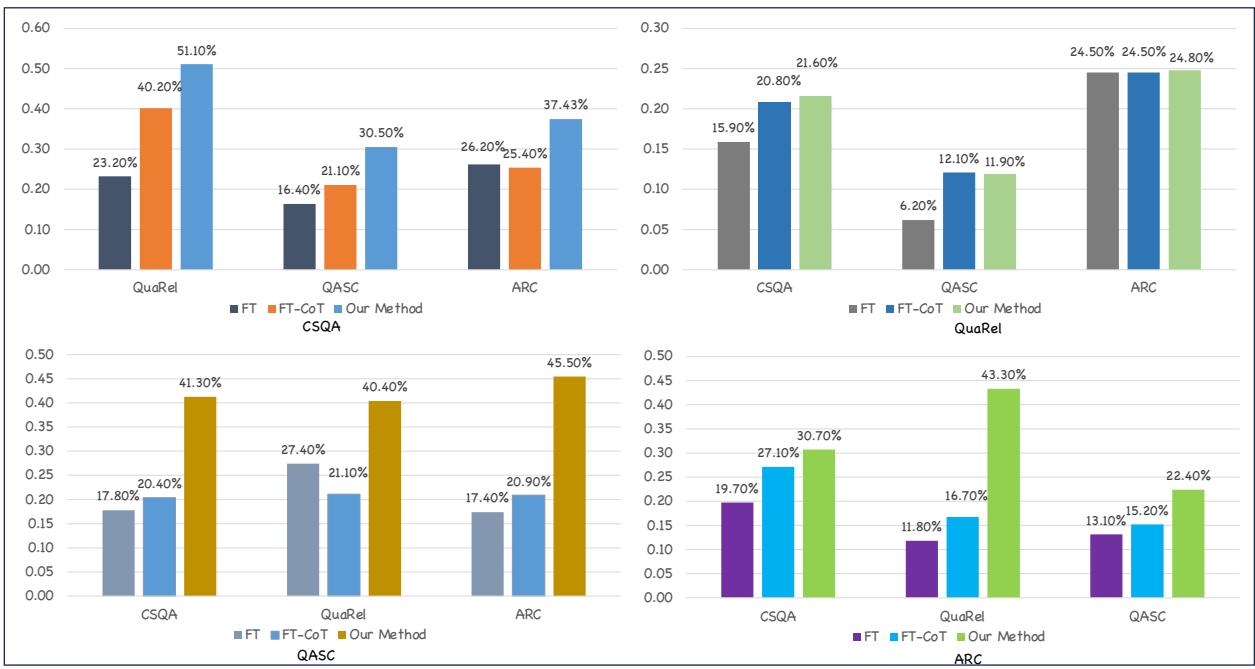
图 5 清楚地展示了所提方法的鲁棒性 (由每组中的第三个柱状图表示) 。当在 CSQA、QASC 或 ARC 上训练时,反事实方法明显优于基线 (FT-CoT) 。这证实了模型不仅仅是在死记硬背;它正在学习可迁移的推理结构。
- (注: 当在 QuaRel 上训练时,性能增益较小,这可能是因为 QuaRel 是一个较小的数据集,且具有不同的二选一格式,使得所有方法的迁移都更加困难。) *
3. 跨架构的通用性
这种方法是专门针对 GPT 风格的模型的吗?为了找出答案,研究人员将其应用于像 BART 和 T5 这样的编码器-解码器模型。
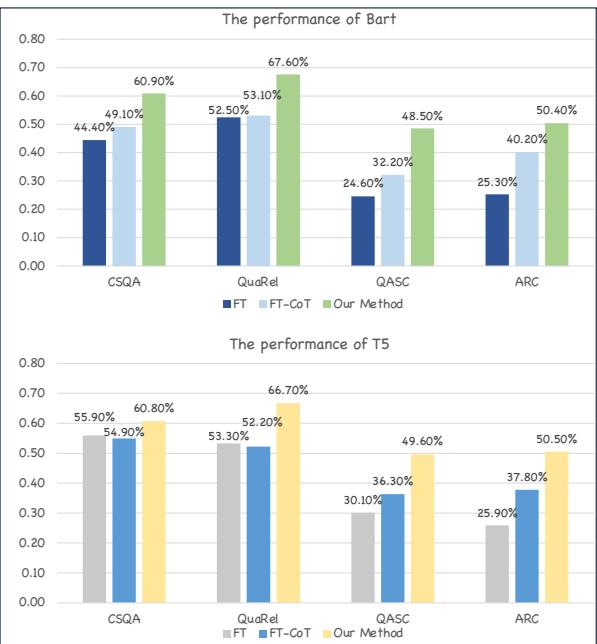
图 6 显示增益是一致的。无论是使用 BART 还是 T5,“Our Method”柱 (绿色) 都显著高于标准 CoT 基线 (橙色) 。这表明该框架是小语言模型的通用增强器。
为什么它有效?定性分析
为了真正弄清楚为什么这行得通,让我们来看一下新方法与旧方法生成的推理过程的定性比较。
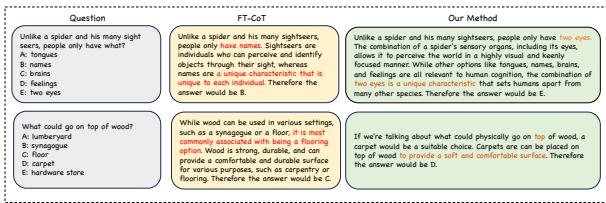
图 7 提供了两个具有启发性的例子:
- “人类 vs 蜘蛛”的问题:
- FT-CoT (基线) : 模型关注短语“two eyes (两只眼睛) ”并选择了它。虽然答案在技术上是正确的,但推理很肤浅。
- Our Method (我们的方法) : 模型生成了更丰富的解释: “人类通过感官感知世界……包括视觉……拥有两只眼睛。” 它将“sighters (视觉器官) ”的概念与“视觉”和“眼睛”联系了起来。
- “木头在木头上”的问题:
- 问题问木头放在木头上的哪里。
- FT-CoT 选择了“floor (地板) ”,因为木头和地板是常见的搭配。
- Our Method 解释了为什么: “地板提供了一个舒适的表面……通常铺设在其他木质表面之上。”
通过在反事实样本上进行训练,模型学会了单词之间的关系是由世界规则 (因果关系) 支配的,而不仅仅是它们在句子中相邻出现的频率。
结论与启示
这项研究强调了我们训练小型 AI 模型方式中的一个关键局限性。如果学生模型只是在死记硬背老师的话而不理解其中的逻辑,那么仅仅从大模型中“蒸馏”答案甚至推理过程是不够的。
通过引入反事实蒸馏 , 研究人员找到了一种在训练期间对学生模型进行“压力测试”的方法。
- 反事实迫使模型寻找因果触发因素,而不是表面模式。
- 多视角 CoT 赋予模型通过排除法验证答案的能力,模仿人类的批判性思维。
对于 NLP 领域的学生和从业者来说,这篇论文提供了一个宝贵的教训: 数据质量和多样性 (特别是因果多样性) 比单纯的数据量更重要。 你并不总是需要更大的模型来获得更好的推理能力;有时候,你只需要教小模型去问“如果……会怎样?”和“为什么不?”