](https://deep-paper.org/en/paper/file-3714/images/cover.png)
ChatGPT、GPT-4 和 Claude3 等模型的发布标志着历史的一个转折点。我们现在拥有的人工智能能够写诗、调试代码并起草学术论文,其熟练程度可以与人类媲美,有时甚至超越人类。
但这令人惊叹的技术也投下了长长的阴影。滥用的可能性是巨大的,从大学里的学术不端到社交媒体上错误信息的大规模生产。随着这些“大规模欺骗武器”变得越来越复杂,人类作者和机器作者之间的界限变得模糊不清。
这产生了一个紧迫的需求: 我们如何可靠地检测由大语言模型 (LLM) 编写的文本?
在这篇文章中,我们将深入探讨一篇引人入胜的研究论文,题为 《文本透视: 通过内在特征检测 LLM 生成的文本》 (Text Fluoroscopy: Detecting LLM-Generated Text through Intrinsic Features) 。 研究人员提出了一种新颖的方法,不再局限于查看文本的表面或其最终含义。相反,他们深入神经网络的“内部”——特别是中间层——去寻找作为 AI 生成数字指纹的“内在特征”。
当前检测器存在的问题
要理解为什么需要这种新方法,我们首先需要看看当前的检测系统是如何失败的。通常,现有的检测器分为两大阵营:
- 语义检测器 (“意义”方法) : 这些检测器关注语言模型 (如 BERT 或 RoBERTa) 的最后一层 。 最后一层包含抽象的、语义上的信息——即文本的“意义”。
- *缺陷: * 人类和 AI 的文本通常有着相同的含义。如果你要求 AI 写一篇关于气候变化的文章,其语义内容看起来会与人类写的相关文章非常相似。这些检测器往往会过拟合于特定主题,并在遇到新领域时失效。
- 语言学检测器 (“句法”方法) : 这些检测器关注第一层或使用统计模式 (n-gram) 。它们分析词频和简单的语法结构。
- *缺陷: * 这些特征很脆弱。如果攻击者仅仅是对文本进行改写 (替换同义词或改变句子结构) ,这些检测器通常就会崩溃。
文本透视 (Text Fluoroscopy) 背后的研究人员认为,只看开头 (语言学) 或结尾 (语义) 是不够的。真正的秘密在于两者之间的过程。
核心洞察: “中间”很重要
当大语言模型 (LLM) 处理文本时,它是分层进行的。
- 早期层处理简单的句法和单词定义。
- 后期层构建复杂的、抽象的意义。
研究人员假设中间层捕捉了过渡过程——即单词是如何组成句子的。这个中间阶段反映了模型独特的“思维过程” (或计算过程) 。虽然人类和 AI 最终可能会得到相同的语义含义 (最后一层) ,但 AI 通过其神经网络到达那里的路径是根本不同的。
研究人员将这些在中间层发现的特征称为内在特征 (Intrinsic Features) 。
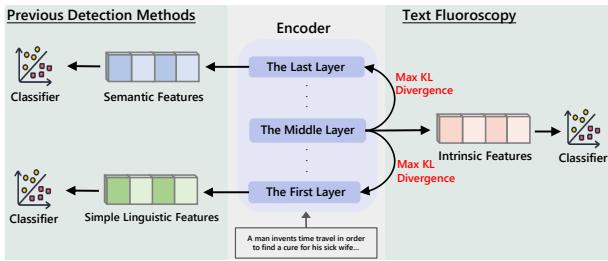
如图 1 所示,以往的方法依赖于网络的极端两端。而文本透视则针对具有“最大 KL 散度 (Max KL Divergence) ”的层——本质上,就是那个与原始输入和最终输出都最为不同的层。
文本透视: 它是如何工作的
让我们分解一下这个方法的机制。它作为一个“黑盒”检测器运行,意味着它不需要访问生成文本的特定模型 (如 GPT-4) 的内部权重。相反,它使用一个独立的、开源的模型( 编码器 )来分析可疑文本。
第一步: 设置
系统接收一段文本 \(x\)。它将这段文本通过一个预训练的语言模型 (编码器) ,该模型有 \(N\) 层。
第二步: 投射到词汇表
通常,语言模型只有在通过所有层处理文本后才预测下一个单词 (Token) 。然而,文本透视强制模型利用每一层可用的信息来预测下一个单词。
对于任意给定的层 \(j\),该方法计算下一个 Token 的概率分布。这本质上是在问: “仅根据你在第 10 层知道的信息,你认为下一个词是什么?”
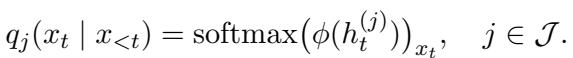
这里,\(q_j\) 是第 \(j\) 层的概率分布。
第三步: 寻找“内在”层
这是最关键的一步。系统不仅仅是随机选择一个中间层。它动态地搜索代表信息处理中最大“变化”的那一层。
它将候选层 (\(q_j\)) 的概率分布与两个基准进行比较:
- 第一层 (\(q_0\)) : 代表原始、浅层的语言信息。
- 最后一层 (\(q_N\)) : 代表最终、抽象的语义信息。
它使用一种称为 Kullback-Leibler (KL) 散度的数学度量来计算这些分布之间的差异。目标是找到那一层 \(M\),使其与起点和终点的差异都最大化。
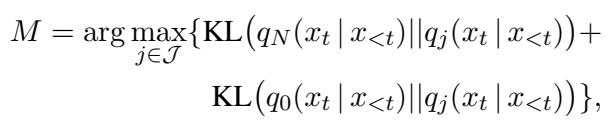
通俗地说: 我们要找的那一层,既最不像原始输入,也最不像最终输出。这一层包含了模型独特的“计算风格”——即内在特征。
为了直观地理解为什么这行得通,请看下图。它显示了不同层之间的 KL 散度 (左) 与检测准确率 (右) 之间的关系。
注意到这种相关性了吗?KL 散度在较深层 (大约第 25-30 层) 达到峰值,而检测准确率 (AUROC) 也遵循完全相同的趋势。这证实了数学上最独特的层确实也是检测 AI 文本的最佳层。
第四步: 分类
一旦确定了最佳层 \(M\),系统就会从该层提取“隐藏状态”特征 (\(h\)) 。这些特征被输入到一个简单的分类器中以做出最终决定: 人类还是 AI?
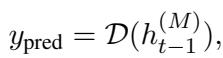
分类器使用标准的损失函数进行训练以最小化误差。
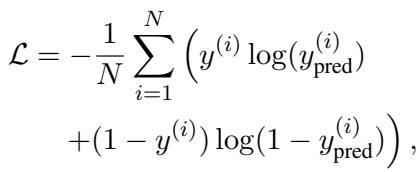
实验与结果
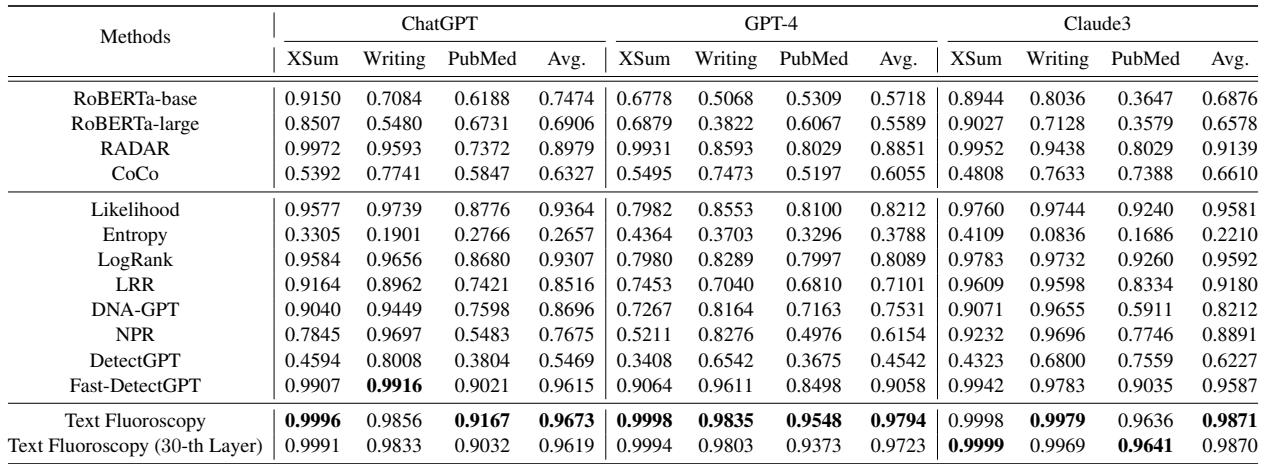
这个理论在实践中站得住脚吗?研究人员在一系列最先进的检测器面前测试了文本透视,包括 RADAR、Fast-DetectGPT 以及像 RoBERTa-large 这样的商用检测器。
他们使用了三个多样化的数据集:
- XSum: 新闻摘要。
- WritingPrompts: 创意故事写作。
- PubMedQA: 生物医学问答。
并且针对三个强大的生成器进行了测试: ChatGPT (GPT-3.5)、GPT-4 和 Claude3 。
卓越的检测性能
结果具有压倒性的优势。文本透视的表现始终优于基线。
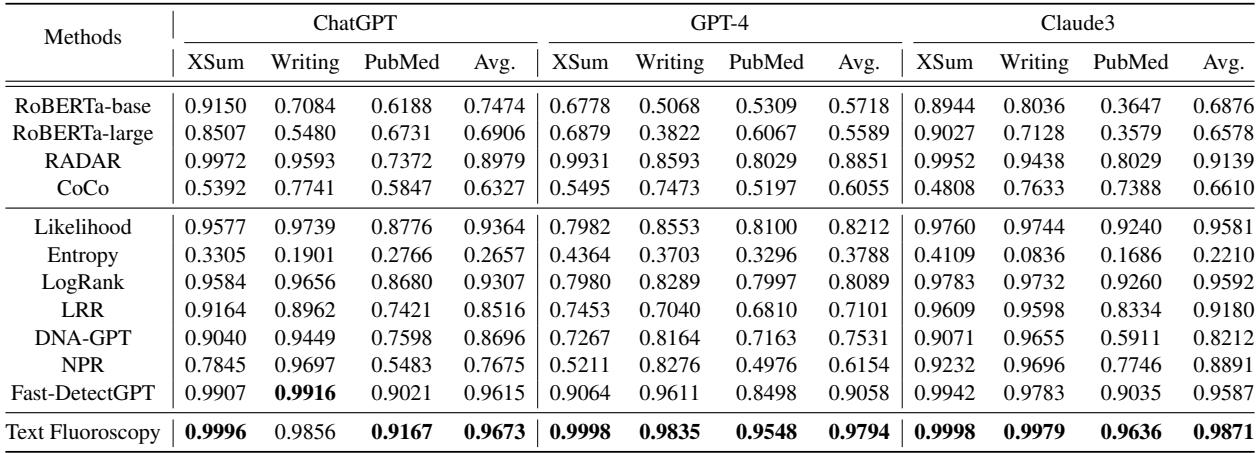
从表 1 中得出的关键结论:
- GPT-4 检测: 对大多数检测器来说,这都是出了名的困难。文本透视的平均表现比最佳基线 (Fast-DetectGPT) 大幅提升了 7.36% 。
- 一致性: 它在几乎所有模型和领域中的 AUROC 得分都超过了 96%。 (AUROC 是一个指标,1.0 代表完美,0.5 代表随机猜测) 。
为什么“中间”优于“开头”或“结尾”
研究人员进行了消融实验,以证明中间层确实在发挥关键作用。他们将动态中间层选择方法与简单地使用同一编码器的第一层或最后一层进行了比较。
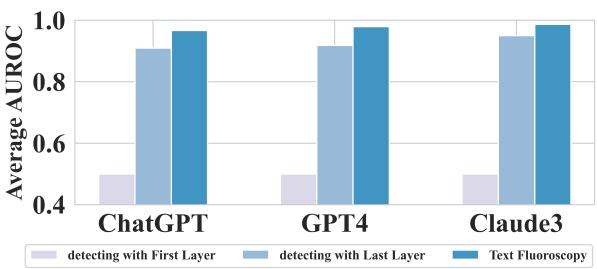
如图 2 所示,“文本透视 (Text Fluoroscopy) ”的柱状图 (蓝色) 始终高于使用第一层 (绿色) 或最后一层 (橙色) 。这验证了中间层的内在特征比语义或语言特征更具区分度的假设。
对抗攻击的鲁棒性
当前检测器最大的弱点之一是容易被欺骗。如果你要求 AI 改写它自己的文本,或者如果你将文本翻译成中文再翻译回英文 (回译) ,检测指纹通常会消失。
因为文本透视关注的是内在特征——即文本的深层结构处理——所以它对这些攻击具有显著的抵抗力。在他们的测试中,即使使用名为 DIPPER 的工具对文本进行激进的改写,文本透视仍保持了近 99% 的准确率 , 而其他工具则出现了大幅下降。
局限性与未来优化
有一个问题: 速度。
因为原始方法需要计算每一层的概率分布以找到最大 KL 散度,所以它需要更多的计算量。
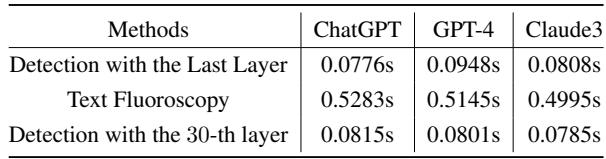
如表 4 所示,完整的文本透视方法每处理一段文本大约需要 0.5 秒 , 而标准的最后一层检测大约只需 0.08 秒 。 虽然 0.5 秒对于单个用户来说足够快,但对于处理数百万条推文来说可能太慢了。
解决方案: 硬编码层数。 研究人员分析了哪一层最常被选中。他们发现检测性能通常在他们编码器的第 30 层左右达到峰值。
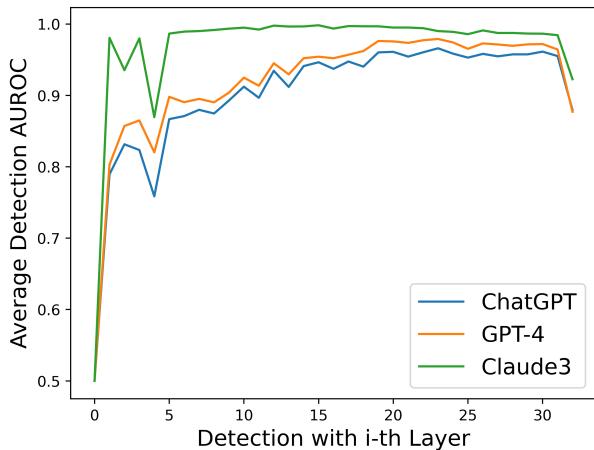
通过简单地将方法固定为始终使用第 30 层 (跳过动态搜索步骤) ,他们实现了巨大的速度提升——使其几乎与标准方法一样快——同时准确率下降不到 0.7% 。 这种“文本透视 (第 30 层) ”变体为实际部署提供了一个实用的平衡点。
结论
“文本透视”论文在 AI 生成与 AI 检测的军备竞赛中迈出了重要的一步。它挑战了我们需要查看文本的“意义”来识别作者的传统智慧。
相反,它教会我们过程与结果同样重要。通过窥探语言模型的中间层——句法转化为语义的数字突触——我们可以找到稳健的内在指纹来识别机器生成的文本,即使这些文本经过了精心的伪装或修饰。
随着像 GPT-4 和 Claude3 这样的 LLM 继续进化,像文本透视这样依赖于模型基础架构而非表面模式的技术,对于维护数字内容的信任将至关重要。