](https://deep-paper.org/en/paper/file-3722/images/cover.png)
引言
想象一下,你试着教一个孩子说话,但你只能指着白色背景上的单个孤立物体。“猫”、“椅子”、“苹果”。孩子可能会完美地学会这些物体的名字。但是,当你向他们展示一只睡在椅子上的猫,或者一个放在猫旁边的苹果时,会发生什么呢?
语言不仅仅是给事物命名;它是关于描述事物之间的关系的。这就是组合性 (Compositionality) 的挑战——即将简单的单元 (如单词) 组合成复杂含义 (如句子) 的能力。
在 AI 和语言涌现 (Language Emergence) 领域,研究人员训练人工智能体相互交流以完成任务。多年来,标准的“指称游戏 (Referential Game) ”看起来很像那个受限的育儿场景: 智能体只针对单个实体进行交流。虽然这让我们学到了很多关于通信协议如何从零开始涌现的知识,但它缺乏现实世界的复杂性。现实场景包含多个实体,而且它们之间的空间关系至关重要。
在这篇深度文章中,我们将探索一篇引人入胜的研究论文,题为 《多实体指称游戏中组合语言的涌现: 从图像到图表示》 (The Emergence of Compositional Languages in Multi-entity Referential Games: from Image to Graph Representations) 。 研究人员提出了一个新的、更复杂的游戏,涉及多个实体,并探讨了一个基本问题: AI “看”世界的方式——是作为原始像素还是作为结构化的图——是否会改变它所发明的语言种类?
背景: 指称游戏与输入难题
在剖析新方法之前,我们需要了解这些 AI 智能体生存的“游乐场”。
经典的指称游戏
这个设置借鉴了博弈论和语言学 (特别是刘易斯信号博弈) 。它涉及两个神经网络:
- 发送者 (Sender) : 看到一个目标物体,并向接收者发送一条消息 (一串符号) 。
- 接收者 (Receiver) : 读取消息,并试图从一排“干扰项”中选出正确的目标物体。
如果接收者选对了物体,两个智能体都会获得奖励 (或最小化损失函数) 。经过成千上万轮的训练,它们会发展出一套共享的协议——一种语言——来描述这些物体。
“组合性”圣杯
如果一个智能体看到一个红色的圆形并说“glorp”,看到一个蓝色的方形并说“fip”,它就学会了名字。但如果它看到一个红色的方形,我们希望它能说出类似“glorp-fip” (红-方) 的内容。这就是组合性 。 这意味着语言是有结构的: 消息的部分系统地指代输入的部分。
之前的研究遇到了一个障碍:
- 图像 (像素) : 当智能体观察原始图像时,它们很难发展出组合性语言。数据是“纠缠 (entangled) ”的——一个“红色方形”只是一堆彩色像素;“红色”和“方形”的概念并没有显式分离。
- 特征向量: 如果你给智能体提供一个特征列表 (例如
[颜色=红, 形状=方]) ,它们很容易发展出组合性语言。然而,特征向量无法扩展。你不能轻易地用一个固定大小的向量来表示一张可能包含一只猫,或者五只猫和一条狗的图像。
解决方案?图 (Graphs) 。
这篇论文的作者提出图作为“恰到好处”的解决方案。
- 像特征向量一样,图是解耦 (disentangled) 的。代表“猫”的节点与代表“在…上面”的节点是截然不同的。
- 像图像一样,图具备良好的扩展性 。 你可以使用图神经网络 (GNN) 来表示包含许多实体的复杂场景,而无需改变基础架构。
核心方法: 双实体记
为了验证他们的假设,研究人员设计了一个新的“多实体指称游戏”。发送者不再是描述单个物体,而是必须描述一个包含两个实体的场景,这两个实体被放置在一个 4 位置的网格中 (左上、右上、左下、右下) 。
例如,一个目标可能是: 一只老鹰在左上角,一只兔子在右下角。
智能体必须学会交流的不仅仅是网格里有什么 (形状) ,还有它们相对于彼此在哪里 (空间关系) 。
通信架构
通信过程使用循环神经网络 (RNN) 在数学上进行了结构化。
发送者 接收一个输入项 (\(I_t\)),将其处理成向量表示 (\(f_S(I_t)\)),并使用 RNN 生成一串符号序列 (消息 \(M\)) 。
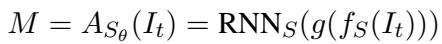
接收者 接收该消息 \(M\),将其通过自己的 RNN 运行,并将结果与潜在目标项 (\(I_1...I_n\)) 的嵌入进行比较。它使用 Softmax 函数来计算每个项目是目标的概率。
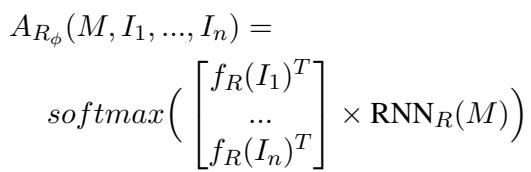
最后,智能体使用损失函数进行联合训练,该函数会在接收者未能识别出正确目标时对它们进行惩罚。
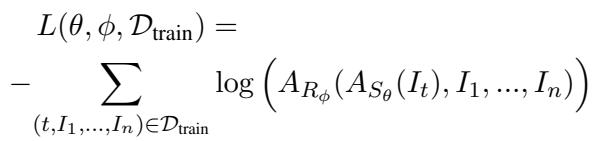
可视化世界: 从像素到图
这是论文最关键的贡献。作者不仅仅测试了“图 vs. 图像”。他们认识到,要构建一个图来表示“老鹰在左上,兔子在右下”这个陈述,有很多种方法。
他们提出了四种截然不同的图模式 (Graph Schemas) , 外加基线的图像 (Image) 表示。
让我们来看看论文中提供的视觉分解:
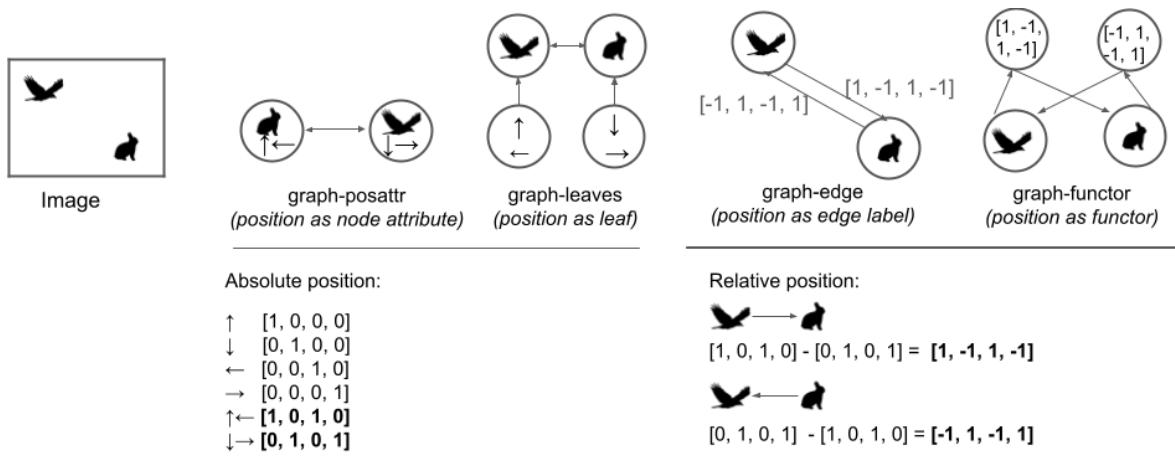
让我们分解图 1 中展示的这四种图表示:
- Graph-posattr (位置作为属性) :
- *概念: * 位置是物体本身的一个属性。
- *结构: * 两个节点 (老鹰,兔子) 。每个节点包含“形状” (老鹰) 和“位置” (左上) 的特征。
- *类比: * 就像戴着一个写着“老鹰”的名牌,同时戴着一顶写着“左上”的帽子。
- Graph-leaves (位置作为叶节点) :
- *概念: * 位置是与物体相连的一个独立实体。
- *结构: * 一个中心的“老鹰”节点连接到一个“左上”节点。
- *类比: * 老鹰手里拿着一个写着“左上”的气球。
- Graph-edge (位置作为边标签) :
- 概念: * 位置由物体之间的关系*定义。它使用相对定位。
- *结构: * 一条边连接老鹰和兔子。边上的标签写着“(-1, 1)” (意味着兔子相对于老鹰在下方 1 格且右方 1 格的位置) 。
- *类比: * 一张地图,老鹰是起点,通往兔子的路径由方向描述。
- Graph-functor (位置作为函子) :
- *概念: * 一种逻辑、函数式的方法。
- *结构: * 一个“函数”节点 (代表相对位置,如“左上方”) 指向两个实体。
- *类比: * 一个数学函数 \(f(x, y)\),其中 \(f\) 是位置,而 \(x, y\) 是动物。
图像模型主要作为基线,使用卷积神经网络 (CNN) 直接观察像素网格。
实验与结果
研究人员使用这五种不同的输入表示 (图像 + 4 种图) ,在不同难度的游戏中训练了成对的智能体。难度通过改变干扰项的数量 (游戏规模) 和允许的最大消息长度来调整。
1. 它们能互相理解吗? (通信成功率)
第一个障碍是基本能力。发送者能否足够好地描述场景,以便接收者将其挑选出来?
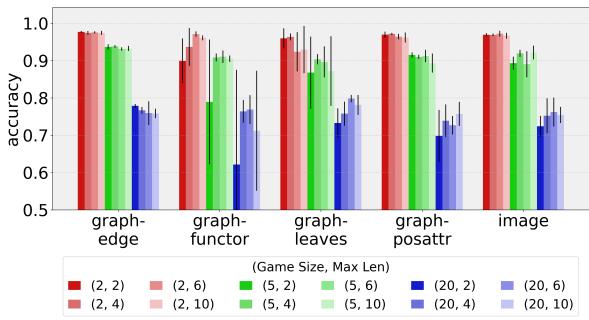
如图 2 所示,答案是肯定的能。
- Y 轴代表准确率 (1.0 = 100%) 。
- 即使在最难的游戏中 (游戏规模 20,意味着 1 个目标和 19 个干扰项) ,准确率通常也保持在 70% 以上。
- 意想不到的赢家:
graph-edge(图-边) 和image(图像) 表示通常表现最好。 - 结论: 无论是基于像素还是基于图的智能体,都有能力解决复杂的多实体任务。
2. 它们说的是结构化语言吗? (组合性)
这是分析深入的地方。为了衡量语言是否像“人类语言” (具有组合性) ,作者使用了一个称为拓扑相似度 (Topographic Similarity, topsim) 的指标。
topsim如何工作: 它比较“意义空间”中的距离与“消息空间”中的距离。- *例子: * 如果“老鹰-左”和“老鹰-右”是相似的场景 (距离很小) ,它们的消息也应该是相似的 (例如,“glorp-fip”和“glorp-bop”) 。如果消息完全不同 (“glorp” vs “zazzle”) ,那么
topsim分数就会很低。
研究人员将涌现出的语言与“完全组合性”的脚本 (例如,一个实际上说“老鹰 左上 兔子 右下”的脚本) 进行了比较。
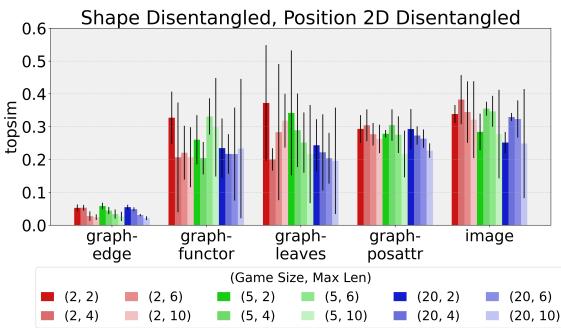
图 3 揭示了一些意想不到的事情。
- 大多数模型获得了中等的分数 (大约 0.2 - 0.3) 。这表明有一些结构,但不完美。
- 异常值:
graph-edge模型 (最左边的蓝色条) 在许多配置下的组合性分数明显低于其他模型。
等一下,graph-edge 不是有很高的准确率吗?是的。这意味着 graph-edge 智能体有效地解决了任务,但使用了一种不能清晰映射到人类风格的“物体 + 位置”描述的语言。
3. 侦探工作: 它们到底在说什么?
为了理解为什么组合性分数是中等的,作者在意义空间上进行了“消融研究”。他们再次计算了 topsim,但这次他们操纵了“基准真相 (ground truth) ”,看看智能体关注的是什么。
他们测试了两种情况:
- 仅形状 (Shape Only) : 无论位置如何,语言是否跟踪动物的身份 (老鹰 vs 兔子) ?
- 仅位置 (Position Only) : 无论动物是什么,语言是否跟踪位置 (左上 vs 右下) ?
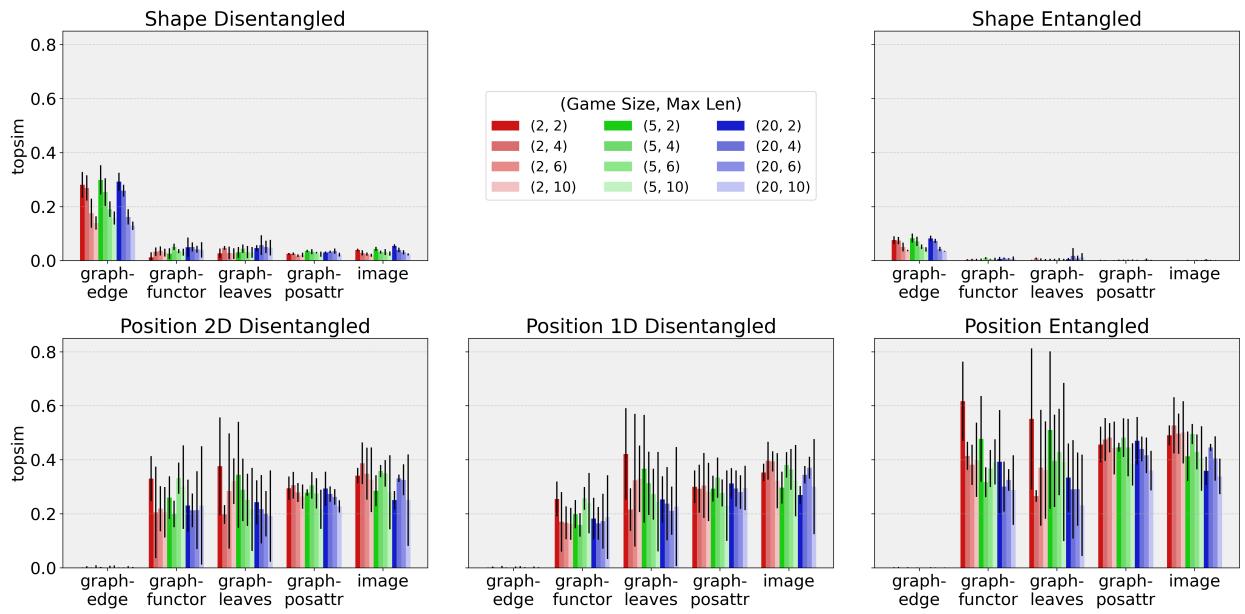
图 4 是这篇论文的“确凿证据”。看看列之间的区别。
第 1 列 (形状解耦) : 看左上角的图。
graph-edge模型 (最左边的条) 在这里得分非常高。*解释: * 使用
graph-edge的智能体非常擅长命名形状 。 它们对于“老鹰”和“兔子”有不同的词。第 1 列 (2D位置解耦) : 看左下角的图。
graph-edge模型得分接近于零。*解释: *
graph-edge智能体本质上忽略了独立的位置描述 。图像和其他图的反转:
image、graph-posattr、graph-leaves和graph-functor模型显示出相反的趋势。它们在纯形状上的得分较低,但在位置上的得分较高。这表明这些智能体可能优先考虑东西在哪里,而不是它们是什么,或者可能将形状“纠缠”进了位置中。
“纠缠”假说
作者挖掘得更深 (图 4 的第 3 列) 。他们检查了智能体是否将两个位置视为一个单一的概念 (例如,用一个特定的词来表示“左上 和 右下”在一起) ,而不是两个独立的坐标。
数据表明,对于位置,智能体确实倾向于纠缠 。 它们倾向于描述整个网格的配置,而不是单独描述每个实体的位置。这就解释了为什么它们能完成任务 (它们识别出了网格布局) ,但未能通过标准的组合性测试 (该测试期望“左上”和“右下”是分开的词) 。
4. 语言的演化
最后,这是如何随时间发展的?它们是先从形状开始,后学位置吗?
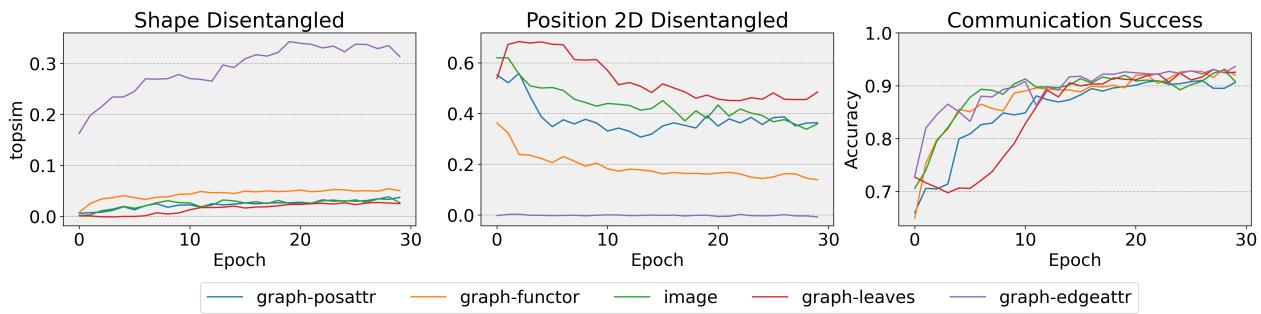
图 5 展示了 30 个轮次 (epochs) 内的训练进展。
- 准确率 (底部图表) : 所有模型都迅速飙升。它们很快就学会了玩这个游戏。
- 组合性 (顶部图表) :
- 顶部图表中的紫色线 (
graph-edge) 显示形状组合性稳步增加。它慢慢学会了分离物体。 - 中间图表中的红色线 (
graph-leaves) 以较高的位置组合性开始,但实际上略有下降。看来随着智能体在游戏中变得更好,它可能会为了专门的“捷径”而牺牲清晰的位置语言。
结论与启示
这篇论文向更现实的 AI 通信迈出了重要一步。通过从单物体场景转向多实体场景,研究人员揭示了智能体在命名事物和命名关系之间所做的复杂权衡。
主要收获:
- 多实体游戏是可解的: AI 智能体可以成功地交流复杂的空间关系,无论它们看的是像素还是图。
- 没有“完美”的输入:
- Graph-edge 表示促使智能体非常擅长命名物体 (形状) ,但不擅长系统地描述位置。
- 图像和其他图类型促使智能体关注空间布局 (位置) ,通常将整个网格配置视为单一概念,而不是组合的部分。
- “句法”鸿沟: 一种完全像人类的语言需要一种机制将特定实体链接到特定位置 (例如,“老鹰在左上角”) 。虽然智能体发展出了基本的词汇,但它们很难发展出这种水平的句法“胶水”,往往诉诸于纠缠概念以最大化效率。
这项研究强调, 我们要如何向 AI 表示数据,从根本上塑造了它所发展的语言。 如果我们希望 AI 能自然地与我们就世界进行交流,我们可能需要平衡特征解耦 (像图) 与环境整体背景 (像图像) 的输入。AI 语言涌现的未来可能在于结合这些视角——既给智能体看清场景的“眼睛”,又给它理解场景的“概念结构”。